How running AI in “observe only” mode is the difference between a successful deployment and a line stoppage on day one. Klyff supports it from day one
There is a moment in almost every manufacturing AI conversation where the mood in the room shifts. It usually happens after the demo has gone well - the defect detection looks impressive, the ROI numbers stack up, the VP of Engineering is nodding. Then someone from operations asks the question that changes the temperature:
“What happens when it gets it wrong and stops our line?”
It is not a hostile question. It is the right question. A stamping press running automotive body panels produces hundreds of parts per hour. A PCB assembly line runs thousands of boards per shift. A false positive - the AI flagging a good part as defective - does not just slow the line. It triggers a cascade: a line hold, an operator investigation, a supervisor call, and a potential MES exception. In high-volume production, even a 2% false positive rate is not a minor nuisance. It is a productivity problem with a dollar figure attached. Some of our clients had it as high as 6%
This is the question that shadow mode exists to answer. And it is the reason that any serious AI deployment in a manufacturing environment - regardless of the vendor, the use case, or the sophistication of the model - should begin here.
What Shadow Mode Actually Means
Shadow mode is a deployment practice, not a product feature. The concept is straightforward: the AI model runs at full production speed, processing every part, every frame, every sensor reading in real time. It makes decisions - pass, fail, anomaly detected, bearing degradation likely - but those decisions are logged, not acted upon. The line keeps moving. The operators keep working. Nothing changes on the floor.
What changes is what’s happening in the background. Every AI verdict is recorded alongside a timestamp, a part identifier, and the confidence score behind that decision. Over the following weeks, those logged verdicts are compared against the ground truth - human inspector decisions, MES quality records, and end-of-line test results. The comparison builds a picture of how the model actually performs on your specific line, with your specific parts, under your specific process conditions.
After a validation period - typically two to four weeks in a quality inspection context, longer for predictive maintenance - you have real data to answer the operations question. Not a vendor’s benchmark. Not a case study from a different industry. Your own false positive rate, your own detection accuracy, your own missed defect count. At that point, switching to live mode is not a leap of faith. It is a decision backed by evidence.
Why This Matters More in Manufacturing Than Almost Anywhere Else
AI deployments in most software contexts are inherently reversible. A recommendation algorithm that performs poorly gets tuned. A chatbot that gives a bad answer gets corrected. The stakes are low, and the feedback loop is fast.
Manufacturing is different in almost every dimension that matters.
The cost of a wrong decision is immediate and physical. A live AI system that triggers a false line hold on an automotive assembly line can cost tens of thousands of dollars in lost production before the error is even diagnosed. In pharmaceutical manufacturing, a false reject on a batch can trigger a full investigation under GxP regulations. In semiconductor fabrication, the cost of a single wafer run is measured in hundreds of thousands of dollars. The asymmetry between the cost of getting it right and the cost of getting it wrong is enormous.
The process context is unique to each plant. A model trained on PCB defect images from one facility does not automatically transfer to another, even when the boards are nominally identical. Different lighting rigs, different camera angles, different solder paste suppliers, different ambient temperature profiles - all of these shift the statistical distribution of what “normal” looks like. A model that achieves 98% accuracy in validation on historical images may perform very differently when deployed against a live line running a slightly different process recipe. Shadow mode is how you find out before it matters.
The workforce dynamic is different. Operations teams in manufacturing have spent careers building expertise in their processes. They are rightly sceptical of systems that claim to outperform that expertise, particularly when those systems are new, opaque, and controlled by someone else’s software. Shadow mode is not just a technical validation step. It is a trust-building exercise. When an experienced quality engineer can watch the AI’s decisions alongside their own for three weeks and see where it agrees, where it catches things they missed, and where it makes mistakes they would not, they develop a calibrated understanding of the system’s capabilities. That understanding is what makes live deployment sustainable. Operators who understand a system’s limits are far more effective at working with it than operators who are simply told to trust it.
The Ground Truth Problem
Shadow mode is only as useful as the data you compare it against. This is where many AI deployments in manufacturing run into a practical challenge that does not appear in vendor presentations: the human verdict is not always in a format you can easily ingest.
In well-instrumented plants, inspector decisions flow directly into the MES - board serial number, inspector ID, verdict code, timestamp, all logged digitally in real time. In these environments, building a comparison between AI verdicts and human verdicts is largely a data integration exercise. You join the part identifier, and the comparison dashboard builds itself.
But a significant number of manufacturing facilities - including many that are otherwise sophisticated - still record quality decisions on paper travellers, shift log sheets, or informal Excel files. The inspector’s expertise is real and valuable. The data capturing it is not in a form that supports systematic comparison.
This distinction matters because it shapes what a shadow mode deployment actually requires. In a fully digital plant, the comparison is automatic. In a partially digital plant, you may need to give inspectors a simple digital input - a tablet at the inspection station where they scan a barcode and record their verdict - before shadow mode can generate meaningful comparative data. That is a small investment, but it is a real one, and it needs to be scoped honestly at the outset rather than discovered mid-deployment.
There is also a subtler issue: the question of what counts as ground truth. In quality inspection, the temptation is to use AOI output as the baseline for comparison, since it is already digital and available. This is a mistake. AOI is a rules-based system operating on the same visual data as the AI model. Comparing an AI model against AOI measures agreement between two automated systems, not accuracy against reality. The ground truth for a shadow mode comparison should be expert human judgment - ideally from the most experienced quality engineers on the line - because those are the decisions the AI is ultimately being asked to match or exceed.
How Klyff Implements Shadow Mode
Klyff’s approach to shadow mode is built on the architecture that already underpins the platform rather than as a separate capability bolted on afterwards.
At the deployment level, each Inspeqtr model deployment carries an deployment_mode attribute - either shadow or live. This is a server-side setting managed through Klyff’s existing attributes API, which means it can be updated in real time without redeploying the model or interrupting the inference pipeline.
The intelligence sits in Klyff’s Rule Engine. When an inference result arrives from the edge device, the rule chain checks the deployment mode before routing the decision. In shadow mode, the verdict is written to the timeseries store - timestamped, tagged with the board identifier and confidence score - but the downstream action nodes are bypassed entirely. No MES webhook fires. No Andon alert triggers. No line hold is created. The model is watching and recording, but the line runs as if it is not there.
When the deployment mode is set to live, the same inference result takes a different path through the rule chain: MES integration, Andon system alert, work order creation in the CMMS, and all the downstream actions that make the AI operationally meaningful. The transition between the two modes is a single configuration change - surfaced in the Inspeqtr UI as a toggle with a confirmation step - but the underlying architecture means it takes effect immediately and cleanly.
The comparison dashboard sits in Klyff’s Analyzr module. During the shadow period, it surfaces the data that matters: AI verdict versus human inspector verdict for every board inspected, agreement rate over time, false positive rate, false negative rate broken down by defect type, and a trend line showing how model performance evolves across retraining cycles. This is not a vanity dashboard. It is the evidence base for the go-live decision, and it is the document that gets shared with operations management when the question comes up - as it always does - about whether the system is ready.
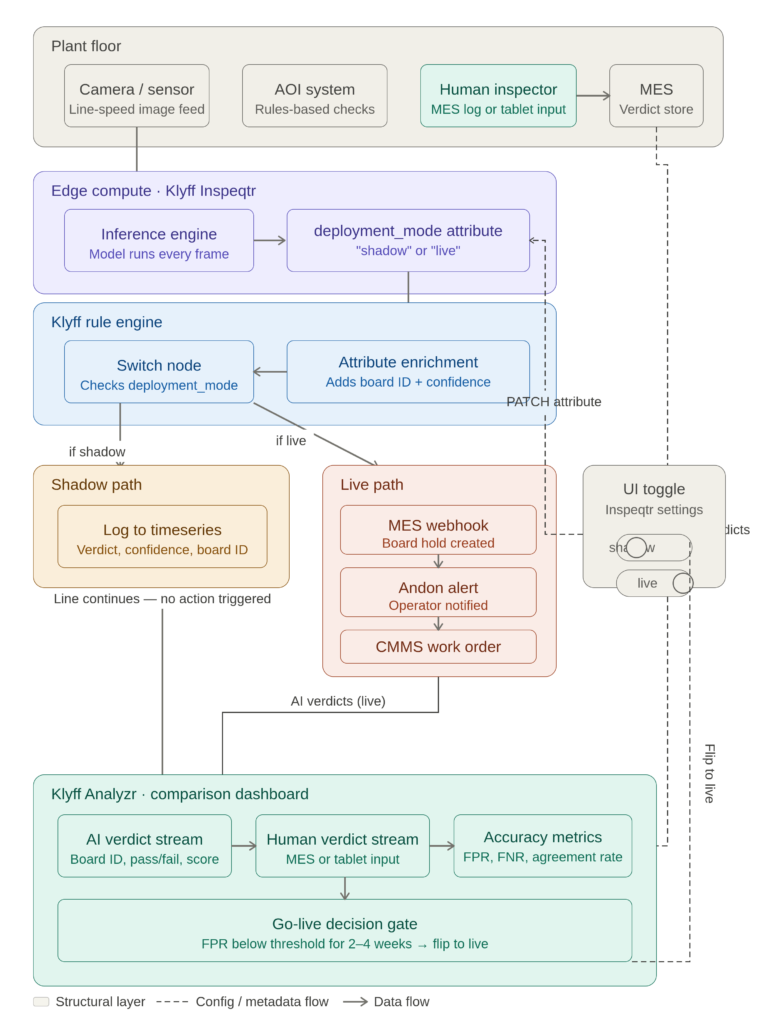
Let us understand through a diagram on how it works for Klyff
Plant floor - the camera feed, the existing AOI system, and the human inspector are all inputs from where the journey starts. The human inspector’s verdict flows into the MES, which feeds the comparison dashboard.
Edge compute / Inspeqtr - the inference engine runs every frame and immediately checks the deployment_mode attribute before doing anything with the result.
Rule engine - this is where the branching happens. The switch node reads the attribute and routes the verdict down one of two paths.
Shadow path (yellow) - verdict is written to the timeseries store with board ID and confidence score. Nothing else. The line keeps moving.
Live path (coral) - verdict triggers the full action chain: MES webhook, Andon alert, CMMS work order.
UI toggle (top right) - the Inspeqtr settings toggle sends a PATCH signal to the deployment_mode attribute, which is what flips the rule engine routing. Shown as a dashed line because it’s a config change, not a data flow.
Comparison dashboard - both the AI verdict stream (from shadow logging) and the human verdict stream (from MES) flow in and are joined on board ID. The accuracy metrics feed the go-live decision gate, which loops back to the toggle when ready.
Shadow Mode as a Continuous Practice, Not Just a Launch Step
One of the less obvious benefits of shadow mode is that its usefulness does not end when you flip to live. Manufacturing processes change. New component suppliers, revised process recipes, seasonal variation in ambient conditions, line speed adjustments - any of these can cause a model that performed excellently during validation to drift in production.
Klyff’s continuous improvement loop treats shadow mode as an ongoing option rather than a one-time gate. When a new model version is trained - triggered by process drift detection, a new defect type, or a routine retraining cycle - it can be deployed in shadow alongside the current live model. The two run in parallel: the live model continues driving production decisions while the new version accumulates a comparison record. Promotion to live only happens when the new version demonstrably outperforms the current one. This means model updates carry the same evidence standard as initial deployment. There is no moment where a production line is suddenly running on an untested model because an update was pushed.
This architecture also handles one of the trickier failure modes in manufacturing AI: silent degradation. A model that is getting gradually worse does not announce itself. Its confidence scores may remain high even as its accuracy on a slowly shifting process drifts downward. Klyff’s drift detection surfaces this early - flagging when model performance on recent production data is diverging from the validation baseline - but the shadow comparison layer provides a second signal. When the AI’s verdicts start diverging from human inspector decisions at a rate above a configured threshold, the system flags it for review before it becomes a quality escape.
The Practical Implication for AI Adoption in Manufacturing
The manufacturing industry is in the early stages of a genuine inflection point in how AI gets deployed on the plant floor. The technology has matured to the point where edge inference, computer vision, and anomaly detection are genuinely production-ready. The models work. The hardware is available. The economics stack up.
The remaining barrier is not technical. It is organisational. Operations leaders need a path to AI adoption that does not require betting their production schedule on a new system’s first day in service. Quality managers need evidence, not confidence intervals from a vendor’s test set. Maintenance engineers need to understand a system’s failure modes before they trust it with their critical assets.
Shadow mode is the mechanism that creates that path. It reframes the adoption conversation to “let’s find out together” rather than “sure it will work”. It gives operations teams the data to make their own go-live decision rather than accepting someone else’s. Also, there is growth in institutional knowledge - among engineers, operators, and managers - that makes live deployment durable rather than fragile.
At Klyff, the principle behind shadow mode reflects something broader about how Manufacturing Intelligence should work: AI on the plant floor earns its place through demonstrated performance on your process, not through benchmark results from someone else’s. The intelligence is in the platform. The evidence comes from your line.
Klyff’s Inspeqtr module deploys on existing cameras and edge hardware with no cloud dependency. Shadow mode is available from day one of deployment. To see a walkthrough of the shadow-to-live transition in a PCB or automotive inspection context, book a technical demo with us