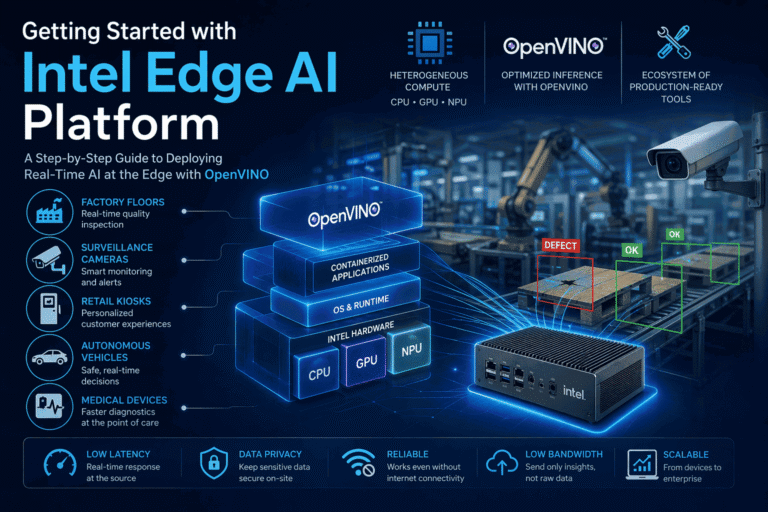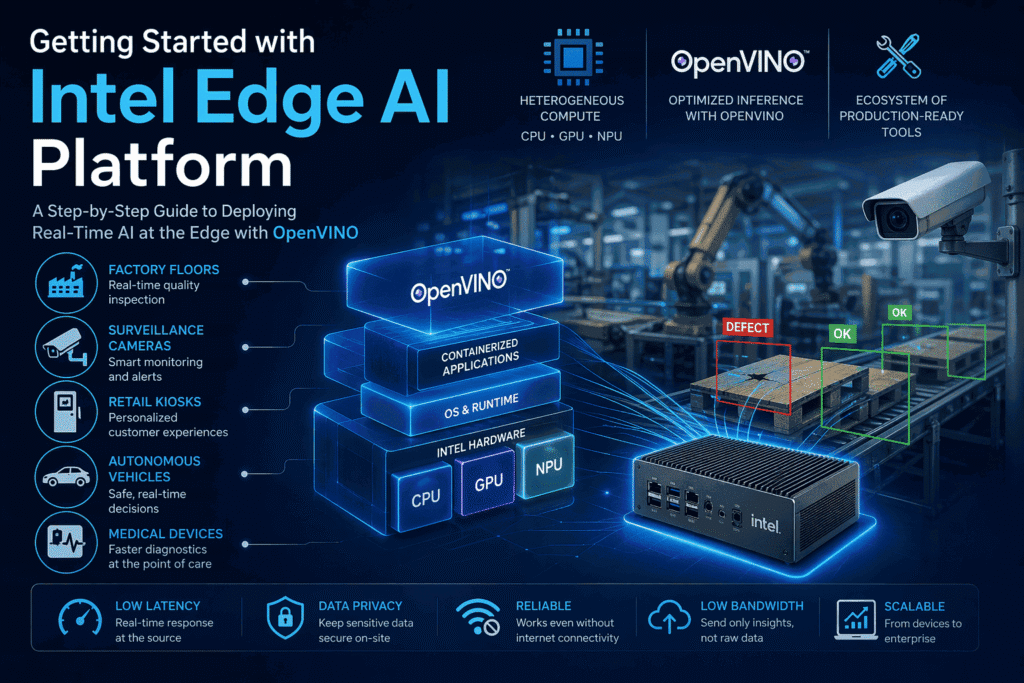
Intel Edge AI platform is a comprehensive suite of tools, hardware, and frameworks designed to deploy artificial intelligence workloads directly at the point of data creation, such as factory floors, surveillance cameras, retail kiosks, autonomous vehicles, and medical devices, rather than relying on distant cloud servers for processing. Klyff is a strategic partner with Intel.
Intel’s Edge AI advantage is built on three key pillars: heterogeneous compute across CPU, GPU, and NPU, the OpenVINO toolkit for optimizing and accelerating inference on Intel hardware, and a rapidly expanding ecosystem of production-ready tools.
This guide introduces the Intel Edge AI Suite step by step, starting from its core architecture and progressing to deploying your first optimized AI model on Intel hardware.
Edge AI — Why It Exists and Why It Matters
It’s important to know why edge AI is even considered to be a different area from cloud AI before attempting to implement any kind of inference solution. It’s easy to see that ignoring the motivation behind edge computing leads to the most costly architectural errors.
The Four Problems That Cloud-Only AI Cannot Solve –
Latency
AI in the cloud results in latency because of the movement of data from and to servers (100–150 ms or higher). This level of latency is unsuitable for real-time applications such as manufacturing, self-driving cars, and healthcare diagnostics. AI at the edge addresses this problem.
Bandwidth
Sending large volumes of data (like video from multiple cameras) to the cloud is costly and often impractical. It can consume massive bandwidth and lead to high data transfer costs. Edge AI solves this by processing data locally and sending only small results instead of raw data, reducing bandwidth usage dramatically.
Data Privacy & Compliance
Many industries (healthcare, finance, manufacturing) have strict rules that prevent sensitive data from leaving their systems. Sending raw data to the cloud can violate regulations and require complex approvals.
Edge AI solves this by processing data locally, ensuring sensitive information stays on-site while only sharing safe, minimal results.
Reliability
Cloud-based AI fails when internet connectivity is lost, which is common in industrial or remote environments.
For critical systems like safety monitoring or access control, this is unacceptable. Edge AI ensures reliability by making decisions locally, even without network connectivity.
What Edge AI Actually Means
Edge AI is the practice of running trained machine learning models on devices physically located at or near the source of data, rather than on remote compute infrastructure. The “edge” is a spatial concept: the boundary between the physical world and the digital network.
Edge devices range from low-power micro-controllers running tiny ML models to powerful edge servers running dozens of concurrent neural network inference pipelines. Intel’s edge AI platform targets the middle and upper tier of this range — devices capable of running production-quality deep learning models with real-time performance guarantees.
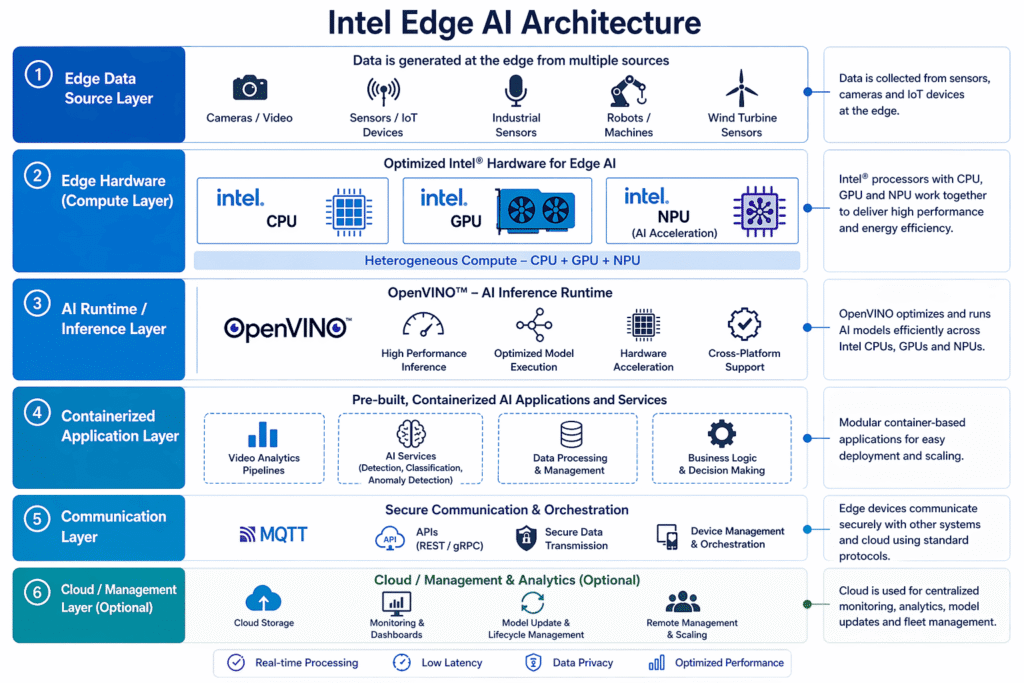
Understanding Intel Edge AI Architecture
The Intel Edge AI platform architecture is designed to bring intelligence closer to where data is generated, enabling real-time processing and faster decision-making. It follows a layered approach, starting with edge devices such as sensors, cameras, and industrial machines that continuously generate data. This data is processed locally on Intel-powered hardware that combines CPU, GPU, and NPU for efficient and optimized performance.
At the core of this architecture is OpenVINO, which optimizes and runs AI models across Intel hardware. It ensures high-performance inference while maintaining flexibility across different devices. On top of this, containerized applications handle tasks such as analytics, anomaly detection, and business logic, making the system modular and scalable.
The architecture also includes a communication layer that enables secure data exchange using standard protocols like MQTT and APIs. Optionally, a cloud or management layer can be integrated for monitoring, model updates, and large-scale deployment.
Overall, Intel Edge AI architecture combines optimized hardware, efficient AI runtime, and scalable applications to deliver low-latency, real-time intelligence at the edge.
Intel Hardware for Edge AI — CPU, GPU, NPU
Intel’s heterogeneous chips offer multiple inference targets. Knowing their strengths helps assign workloads optimally:
CPU (x86 cores): Modern Intel CPUs have AI extensions to accelerate INT8 and BF16 math. CPUs handle general tasks, control logic, and irregular computations. They’re essential for preprocessing/post-processing steps. Inference on CPUs can match some GPU performance for moderate models.
Use CPU when:
No accelerator is present.
Low-latency single inferences on small models.
Fallback for operations not supported on GPU/NPU.
Integrated GPU: Good for massively parallel ops (convolutions, attention). It shares system memory, so it can handle larger models than an NPU but with lower power.
Use GPU for:
High-resolution video or batch inference.
Vision models (ResNet, YOLO) and vision-language models.
Generative models (diffusion, large ViTs)
NPU (Neural Processing Unit): An on-chip fixed-function accelerator optimized for continuous inference at very low power. Use NPU for “always-on” tasks (frame-by-frame classification, keyword spotting) where static batch execution is fine.
Important: NPUs only support static input shapes. The NPU compiler fuses the network into a fixed graph, so dynamic shapes or runtime reshaping aren’t allowed.The NPU plugin auto-enables model caching, so once compiled, future runs are fast.
OpenVINO – The Inference Engine That Runs Everything
OpenVINO (Open Visual Inference & Neural Network Optimization) is Intel’s toolkit for deploying inference for edge-based artificial intelligence applications. This tool takes deep learning models from major frameworks like PyTorch, TensorFlow, ONNX, and others, and converts them into an Intermediate Representation (IR). OpenVINO is used for inference only and does not include any model training process.
Installation
We use the OpenVINO 2025.4 (or newer) Docker or APT-based runtime. For quick setup, one can use the official Docker container:
docker pull openvino/ubuntu20_data_dev:2025.4 # example for Ubuntu20.04 base image
Runtime Basics
In Python, inference follows:
import openvino as ov
core = ov.Core() # Core object manages devices
model = core.read_model("model.xml") # Load optimized IR model
compiled = core.compile_model(model, "CPU") # or "GPU", "AUTO" etc.
infer_request = compiled.create_infer_request()
infer_request.set_input_tensor(input_tensor) infer_request.infer() # sync inference
output = infer_request.get_output_tensor().data
Deep Learning Streamer — Building Video Analytics Pipelines
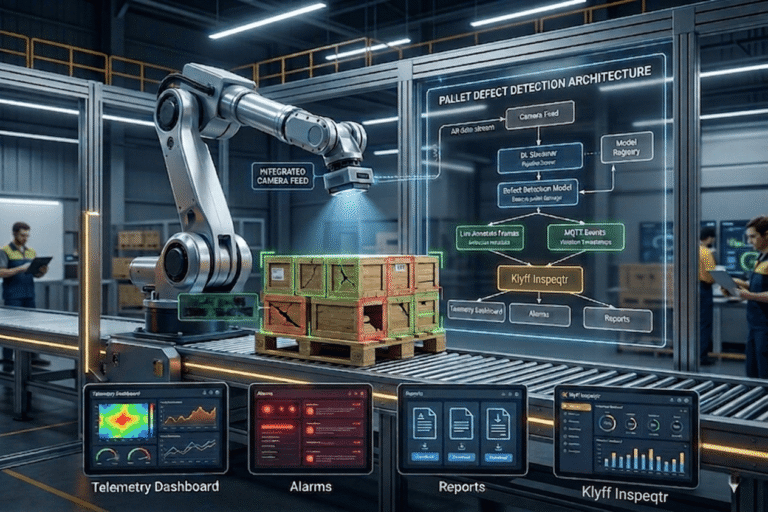
Intel Deep Learning Streamer (DL Streamer) is a GStreamer-based framework for video analytics. It provides pre-built elements (gvadetect, gvaclassify, gvatrack, etc.) that run OpenVINO models inside a media pipeline. This is ideal for our pallet detection use case.
Example Pipeline
Suppose we have a video file and a detection model model. A simple pipeline to detect defects might be:
gst-launch-1.0 filesrc location=${VIDEO_LOCATION} ! decodebin3 ! \
gvadetect model=${MODEL} model_proc=${MODEL_PROC.JSON} device=CPU ! queue ! \
gvawatermark ! videoconvert ! autovideosink sync=false
How Edge AI Talks to the Real World – MQTT
Up to this point, we’ve focused on running AI models at the edge—detecting defects, analyzing video, and generating predictions locally. But inference alone is not enough. A production system must communicate results, receive commands, and integrate with enterprise systems.
This is where MQTT comes in.
MQTT is a lightweight, publish-subscribe messaging protocol designed for:
Low-bandwidth environments
Unreliable networks
Real-time data streaming
Unlike traditional HTTP APIs, MQTT is event-driven, meaning devices don’t constantly poll for updates they receive data instantly when it is published.
Instead of sending the full image, it publishes:
{
"device_id": "camera_01",
"timestamp": "2026-04-24T10:30:00Z",
"defect": "crack",
"confidence": 0.92
}
This message is sent to a topic like:
v1/devices/me/telemetry
In MQTT, a topic is like an address or channel where messages are sent and received.
Monitoring, OTA Updates, and Model Management
In production, you should monitor device health and update models over time:
- Telemetry: The pipeline server and other components emit Prometheus metrics and OpenTelemetry traces. For example, DL Streamer includes FPS and latency metrics.
- Logging: Docker logs for each container (
docker logs dlstreamer-pipeline-server) show inference events. - OTA Updates: Intel’s Edge Manageability (Edge Orchestrator) can push new Docker images or updated configs to devices. You might train a new model offline, build a Docker image with it, and update the deployment via Helm/CI.
- Model Registry: For MLOps, Intel recommends using a model registry to version your models. The pipeline server can pull models from an S3-compatible bucket (MinIO) if set up.
Conclusion
Intel Edge AI platform brings the entire AI pipeline closer to where data is generated, making real-time intelligence practical, scalable, and production-ready. Instead of relying on cloud round-trips, the system processes data locally using optimized Intel hardware and software layers, CPU, GPU, and NPU working together with OpenVINO as the core inference engine.
In practice, this means you can take a trained model and turn it into a fully operational edge application—detecting defects on a factory floor, monitoring safety gear in real time, or analyzing video streams from multiple cameras—while keeping latency low, bandwidth usage minimal, and data secure on-site.
Getting started with Intel Edge AI is less about learning a single tool and more about understanding the full workflow: from model optimization to hardware-aware deployment, to real-time communication and lifecycle management. Once this flow becomes clear, building production-grade edge AI systems becomes a structured engineering process rather than experimental integration.