TL;DR
The manufacturing industry stands at a critical juncture in its digital transformation. While Industry 4.0 has flooded factory floors with sensors, cameras, and Internet of Things (IoT) devices, the true potential of Artificial Intelligence (AI) remains partially unlocked due to a fundamental paradox:
AI craves massive, diverse datasets to learn effectively, yet data privacy, intellectual property (IP) protection, and bandwidth constraints compel manufacturers to keep their data in isolated silos.
Federated Learning (FL) has emerged as the technological bridge across this divide. By enabling machine learning models to train on decentralised data without that data ever leaving its source, FL allows manufacturers to collaborate—across production lines, factories, and even supply chains—without compromising trade secrets. This article examines the mechanics of Federated Learning and offers a comprehensive overview of its applications in Automated Quality Inspection and Predictive Maintenance, supported by real-world case studies and technical architectural insights.
The Data Paradox in Modern Manufacturing
The Centralisation Bottleneck
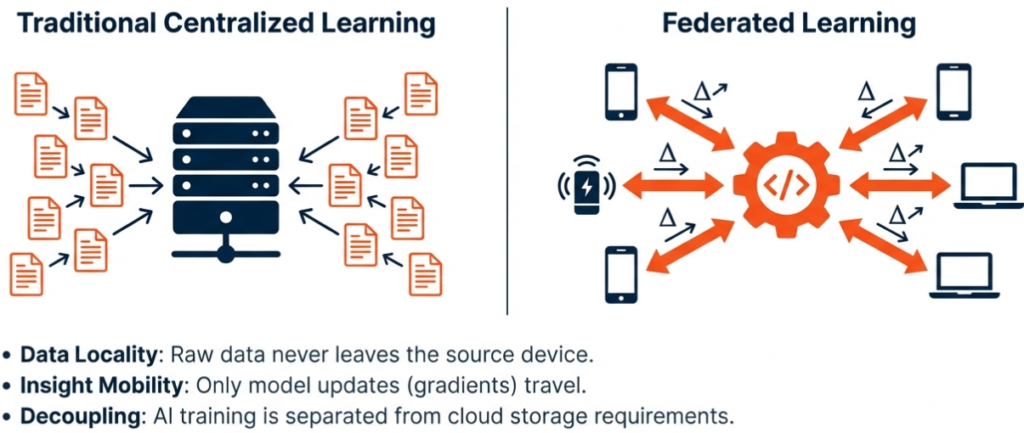
Traditionally, training high-performance machine learning models required a centralised approach. Data collected from edge devices—such as vibration sensors on Computer Numerical Control (CNC) machines or high-resolution cameras on assembly lines—had to be transmitted to a central cloud server or data lake. Once aggregated, this data was used to train a model, which was then deployed back to the edge for inference.
However, in the manufacturing sector, this centralised model faces severe friction:
- Data Privacy and IP: Manufacturing data often contains proprietary information about production processes, formulas, or throughput rates. Sharing this data, even internally between different factory sites, can be restricted by policy. Sharing it with third-party AI vendors or across supply chains is often non-negotiable due to the risk of reverse-engineering or IP theft.
- Bandwidth and Latency: High-frequency sensor data and high-resolution video streams generate massive volumes of information. Transmitting raw data to the cloud is expensive, consumes significant bandwidth, and introduces latency that is unacceptable for real-time process control.
- Data Silos: Data typically resides in “silos”—isolated databases or local servers at specific production sites. This fragmentation means that a model trained on data from Factory A may fail when deployed at Factory B due to slight variations in lighting, equipment, or environmental conditions.
The Federated Solution
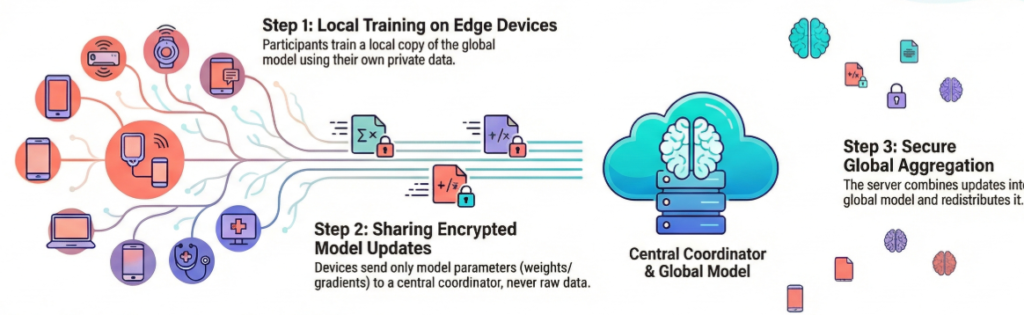
Federated Learning addresses these challenges by flipping the traditional paradigm. Instead of bringing the data to the model, FL brings the model to the data. It is a decentralised approach where the training process occurs locally on edge devices or on-premise servers. Only the mathematical updates (model weights or gradients)—which contain no raw data—are shared with a central coordinator.
This shift enables what was previously impossible: collaborative intelligence without data sharing. It allows manufacturers to harness the collective wisdom of a global fleet of machines while ensuring that raw operational data never leaves the factory floor.
Deconstructing Federated Learning
To understand how FL revolutionises manufacturing, one must understand its core mechanics, algorithms, and variations.
How Federated Learning Works
The lifecycle of a Federated Learning system typically follows a cyclical process comprising five key stages:
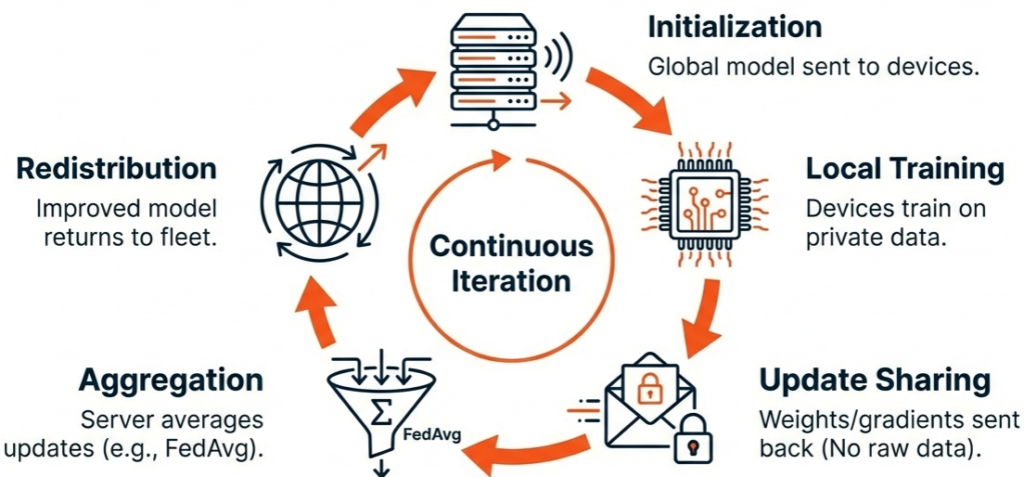
- Model Initialisation & Distribution: A global model (often a pre-trained baseline or a randomly initialised one) is established on a central server or coordinator. This global model is sent to participating client devices (e.g., industrial PCs, edge gateways, or smart sensors).
- Local Training: Each client trains the model locally using its own private, raw data. This training happens on-device, leveraging local compute resources (CPUs, GPUs, or NPUs). The device runs several epochs to improve the model based on its unique dataset.
- Update Sharing: Clients compute the difference between the global model and their locally trained version. They send only these model updates (parameters, weights, or gradients) back to the central server. To further enhance privacy, these updates are often encrypted or obfuscated.
- Aggregation: The central server aggregates the updates from all participating clients using algorithms like Federated Averaging (FedAvg). This creates a new, improved global model that reflects patterns learned from all clients.
- Redistribution: The improved global model is now redistributed to all clients, and the cycle begins again
This cycle repeats for multiple rounds until the model reaches the desired accuracy or convergence.
Types of Federated Learning
In the manufacturing context, FL implementations generally fall into three categories based on how data is distributed:
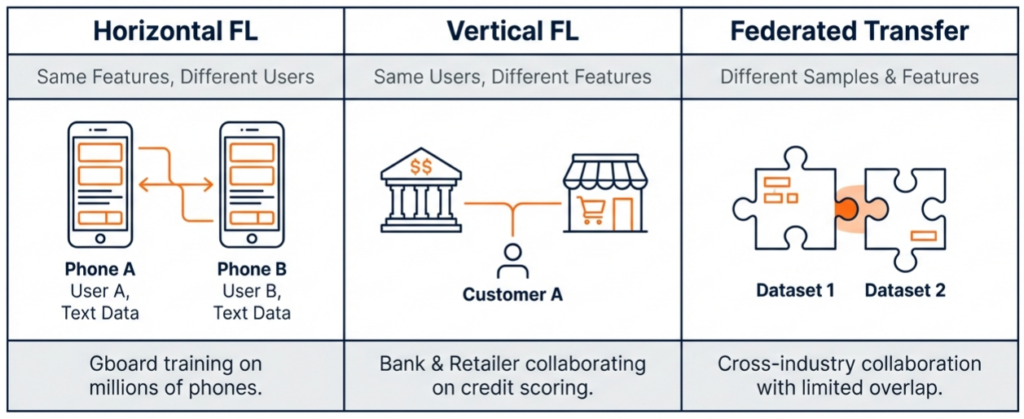
- Horizontal Federated Learning (HFL): This is the most common scenario in manufacturing. It occurs when participants share the same feature space (collect the same type of data) but have different samples (different users or batches).
- Example: Two factories (Factory A and Factory B) both produce Printed Circuit Boards (PCBs) using similar machines. They both have images of PCBs (same features) but different production batches (different samples). HFL allows them to jointly train a defect detection model.
- Vertical Federated Learning (VFL): This applies when participants share the same sample space (same products/users) but have different data features.
- Example: A supply chain scenario where a component manufacturer has production data for a specific serial number, and the final assembler has performance data for that same serial number. VFL allows them to correlate production parameters with final quality without exposing their internal databases.
- Federated Transfer Learning: Used when there is little overlap in both samples and features, utilising transfer learning techniques to leverage knowledge from one domain to improve performance in another.
Core Algorithms
The mathematics of aggregation determines the success of the model.
- FedAvg (Federated Averaging): The standard algorithm where clients perform multiple steps of stochastic gradient descent (SGD) locally and communicate the updated weights to the server, which averages them.
- FedProx: An extension of FedAvg designed to handle “stragglers” (devices with limited resources) and data heterogeneity. It adds a regularisation term to prevent local updates from drifting too far from the global model.
- FedDyn (Dynamic Regularisation): Aims to align the global loss function with local losses generated from heterogeneous devices, enabling faster convergence.
The Engine of Quality: FL in Automated Quality Inspection
Automated Optical Inspection (AOI) systems are standard in modern manufacturing, but they are notorious for high false-call rates (flagging good parts as bad), which necessitates costly manual re-inspection. Federated Learning offers a robust solution to this problem.
The Challenge of Visual Generalisation
A major hurdle in computer vision for manufacturing is data heterogeneity (non-IID data). Lighting conditions, camera angles, and background textures often vary significantly between different production lines or factory sites. A model trained solely on data from Factory A will likely perform poorly at Factory B because it has overfitted to Factory A’s specific environment.
Traditionally, solving this required pooling images from all factories into a central dataset to train a generalised model. However, high-resolution manufacturing images are voluminous and often considered proprietary designs.
Federated Computer Vision in Action: Case Study
A prominent example of this application is found in the collaboration between Siemens and Katulu for Printed Circuit Board (PCB) production.
The Problem: Automated Optical Inspection (AOI) systems at Siemens factories in Erlangen and Amberg were producing false calls. While a centralized XGBoost model was used previously to use process data to reduce these false calls, it failed to generalize. It was too specific to the PCB variants of a single line and required constant adaptation for every new location or product variant.
The FL Solution: Siemens deployed a Federated Learning architecture using the Katulu agent on Industrial Edge devices. Each factory trained a Deep Neural Network (DNN) locally on its own process data and AOI results.
- Architecture: The implementation involved a “field level” (edge devices collecting data via OPC UA), a “factory level” (where the Katulu FL Agent trained local models), and a “public cloud” (where the Katulu Platform aggregated the models).
- Security: To prevent reverse-engineering of the proprietary PCB designs, the system used Differential Privacy, adding noise to the model weights before upload.
The Results: The federated model demonstrated superior generalization capabilities compared to local models.
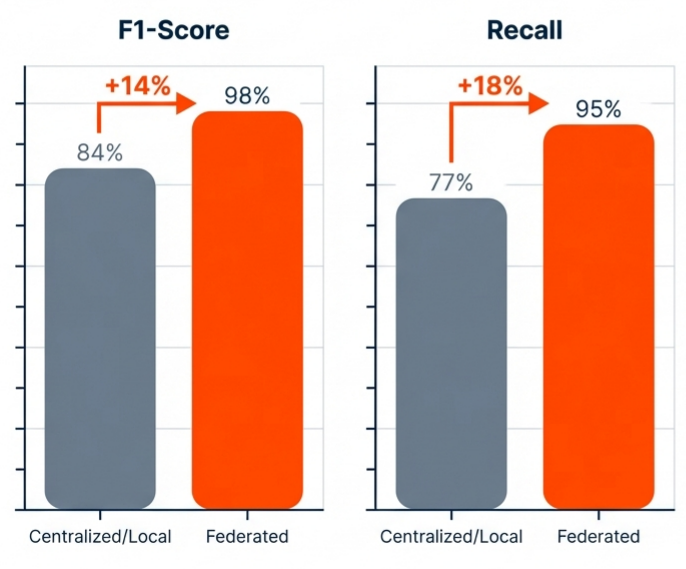
- Performance: The collaboration led to a model F1-Score of 98% (up from 84% on the local model) and a Recall improvement from 77% to 95%.
- Efficiency: Crucially, this was achieved without the raw image or process data ever leaving the individual factory floors, and the model proved robust against local noise in the data.
Broader Benefits for Quality Assurance
- Reduced Data Transfer: Instead of streaming terabytes of video footage to the cloud, only lightweight model weights (often Kilobytes or Megabytes) are transmitted.
- Faster Adaptation: If a new defect type appears in one factory, the local model learns it, and through the next aggregation round, every factory in the network learns to recognise that defect without ever having seen the raw image of it.
- Collaborative Improvement: Even competing manufacturers could theoretically collaborate on a generic defect detection model (e.g., detecting cracks in steel) without revealing the specific products they manufacture.
The Guardian of Uptime: FL in Predictive Maintenance
Predictive Maintenance (PdM) aims to predict equipment failure before it occurs, minimising downtime. Federated Learning is particularly relevant here due to the fragmented nature of failure data.
A case study of a multi-plant automotive components manufacturer highlights the potential:
- 40% Reduction in Scrap Rate: Saving €5,000,000 annually.
- 60% Less Unplanned Downtime: Saving €4,800,000 annually.
- Prevention of Costly Recalls: Saving another €5,000,000 annually.
With an estimated annual investment of €1M, their net benefit was €13.8M—a 1380% ROI.
The Scarcity of Failure Data
Equipment failures are, ideally, rare events. A single factory might not experience enough specific failures of a CNC machine to train an accurate prediction model. This is known as the “imbalanced dataset” problem. However, across a fleet of 1,000 factories using that same CNC machine, there is a statistically significant number of failures.
Cross-Silo Collaboration: Scania Trucks
Research highlights the use of FL for predictive maintenance of air pressure systems in Scania trucks.
- Context: Data was distributed across three different sites.
- Method: An oversampling technique was applied locally to handle the imbalance of failure data. A Machine Learning model was trained to predict potential failures using the DLFi framework.
- Outcome: The federated model matched the performance of centralised models while maintaining the privacy of the fleet’s operational data. This allows for proactive maintenance schedules that reduce downtime and increase efficiency.
The OEM vs. Operator Dynamic
Federated Learning fundamentally changes the relationship between Original Equipment Manufacturers (OEMs) and machine operators (factories).
- Traditional Conflict: OEMs want access to machine data to improve their designs and sell predictive maintenance services. Factories refuse to share this data because it reveals their production volumes and efficiency metrics (trade secrets).
- The FL Compromise: An OEM can deploy an FL model to their machines residing in customer factories. The model learns from the machine’s vibration, temperature, and power usage locally. The OEM receives model updates that help them understand wear-and-tear patterns across their entire global fleet, without ever seeing exactly what their customers are manufacturing or at what rate.
Smart Home and Industrial Analogies
The concept extends to industrial environment monitoring. Similar to how smart thermostats in a “Smart Home” setup can learn heating patterns collaboratively without sending user data to a central cloud, industrial sensors can learn optimal operating temperatures and anomaly thresholds collaboratively. Each sensor trains a tiny neural net locally and shares updates, allowing the entire facility to learn from the habits and anomalies of the whole network.
Technical Architecture and Implementation
Implementing Federated Learning in a manufacturing environment requires a sophisticated stack that spans from the hardware edge to the cloud.
The Infrastructure Stack
- The Field Level (Edge Devices): This layer consists of the physical hardware interacting with the machinery. Devices must have sufficient compute power (RAM and processing) to perform local training, not just inference.
- Hardware: Examples include NVIDIA Jetson devices (Nano, TX2, Xavier), Raspberry Pi 4, or industrial PCs with GPU acceleration. Also relevant are ESP32-based microcontrollers for low-power sensors.
- Role: Collects data via protocols like OPC UA, preprocesses it, and executes the local training loop.
- The Connectivity Layer: Secure communication channels are vital. Protocols like MQTT with TLS, HTTPS, or Time-Sensitive Networking (TSN) are standard for transmitting model updates.
- The Aggregation Server (Cloud/On-Prem): This central coordinator manages the orchestration. It selects which clients participate in a round, aggregates the received weights (using algorithms like FedAvg), and redistributes the global model. Frameworks often use a “Model Registry” to track versions.
Software Frameworks
Several frameworks have emerged to facilitate FL deployment, ranging from open-source research tools to enterprise-grade platforms:
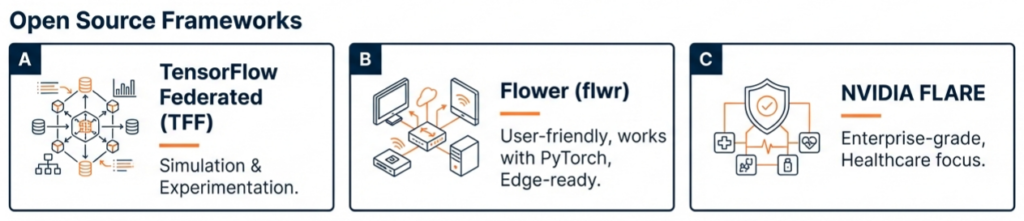
- TensorFlow Federated (TFF): Developed by Google, useful for simulation and experimenting with FL algorithms. It is highly flexible but primarily research-oriented.
- Flower (flwr): A highly flexible, language-agnostic framework that is particularly friendly to edge devices (including mobile and embedded systems). It allows for easy prototyping and works with PyTorch, TensorFlow, and scikit-learn.
- NVIDIA FLARE: Born from healthcare applications (originally NVIDIA CLARA), this framework is robust for enterprise deployment and is battle-tested in industries requiring high security.
- Klyff Senatr: A specialised industrial FL platform. It provides “AutoFL” features to find the best model architecture for distributed private data and manages the “Federated Operations” (FedOps) lifecycle, including bringing the model to the data.
- IBM Federated Learning: Focuses on enterprise security and decentralised training across data sources.
Security Enhancements
While FL inherently protects raw data, advanced attacks (like model inversion) can theoretically reconstruct data from model updates. To counter this, manufacturing implementations often employ:
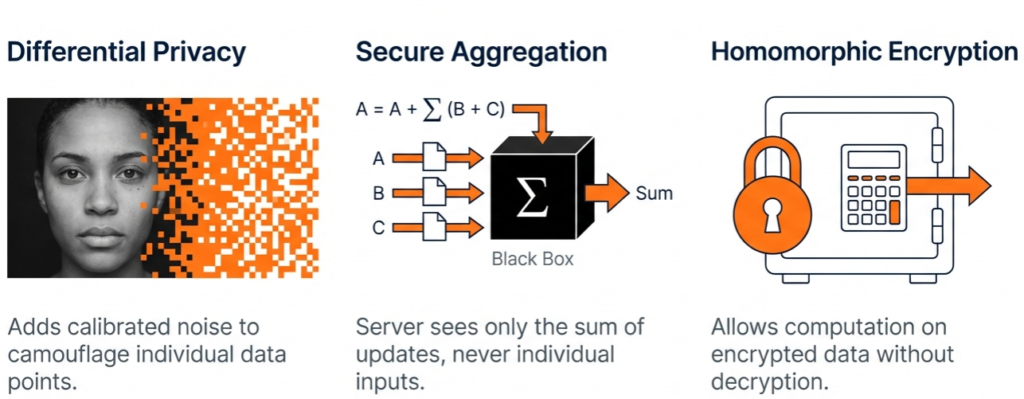
- Differential Privacy (DP): Adding calculated “noise” to the model updates before they are shared. This ensures that the contribution of any single data point cannot be distinguished, preventing reverse-engineering.
- Secure Aggregation: A cryptographic protocol where the server can only decrypt the aggregated result of the updates, never the individual updates from specific clients.
- Homomorphic Encryption: Allows computation to be performed on encrypted data, offering the highest level of security, though often at a computational cost.
Navigating the Challenges
Despite its promise, deploying FL in manufacturing is not without hurdles.

1. Data Heterogeneity (Non-IID Data)
In a perfect world, data across all factories would be “Independent and Identically Distributed” (IID). In reality, manufacturing data is highly non-IID. One factory might produce 90% good parts, while another struggling line produces 70%. One might use a specific sensor brand, while another uses a different one.
- Impact: This statistical divergence can cause the global model to fail to converge or to be biased toward the factory with the most data.
- Solution: Algorithms like FedProx and FedACS (Federated skewness Analytics and Client Selection) add regularization or client selection mechanisms to handle this heterogeneity. Cohorting (grouping similar factories together) is also used to train specialized sub-models rather than one-size-fits-all global models.
2. Systems Heterogeneity and Stragglers
Factory floors are rarely standardized. A fleet might consist of a mix of legacy equipment and modern smart devices with vastly different compute capabilities. Devices with poor connectivity or low battery are known as “stragglers”.
- Impact: Stragglers can bottle-neck the entire training round if the server waits for their updates.
- Solution: Asynchronous Federated Learning allows the server to update the global model as soon as a sufficient number of clients report back, without waiting for the slowest ones.
3. Communication Overhead
While FL saves bandwidth compared to raw data streaming, the frequent exchange of model parameters (especially for large Deep Neural Networks) can still strain limited industrial networks.
- Solution: Model Compression techniques (quantization, sparsification) reduce the size of the update packages. Additionally, reducing the frequency of communication rounds by performing more local training epochs can help balance computation vs. communication.
4. Security Risks: Poisoning and Inference
Bad actors could theoretically inject malicious data (“poisoning”) to corrupt the global model or analyse gradients to infer private data (“inference attacks”).
- Solution: Robust aggregation rules (like Auto-Weighted Geometric Median) can detect and ignore outliers that indicate poisoning. Trusted Execution Environments (TEEs) and hardware-based security offer additional layers of protection.
The Future of Federated Manufacturing
The trajectory of Federated Learning suggests a shift toward more autonomous and resilient industrial systems.
Digital Twins and FL
The integration of FL with Digital Twins (DT) is a burgeoning field. A Digital Twin Edge Network can use device-to-device communication to achieve efficient network management. FL allows these digital twins to learn from their physical counterparts in real-time, enabling highly accurate simulations of factory floors without centralized data aggregation.
Personalised Federated Learning (PFL)
Recognizing that no two factories are identical, the trend is moving toward Personalized Federated Learning. In this model, the global model serves as a base, but each edge device fine-tunes the model locally to adapt to its specific environment (e.g., specific lighting or machine wear). This “meta-learning” approach ensures high global knowledge while retaining local specificity.
Conclusion
Federated Learning represents a paradigm shift for the manufacturing industry, moving it from a model of centralized data hoarding to one of decentralized, collaborative intelligence. By decoupling the ability to do machine learning from the need to centralize data, FL solves the “Data Paradox.”
It enables Automated Quality Inspection systems to learn from global defect libraries while respecting local privacy, resulting in fewer false calls and higher product quality. It empowers Predictive Maintenance strategies to leverage fleet-wide failure data, turning rare local anomalies into globally recognized warning signs. A typical pilot implementation plan might look like
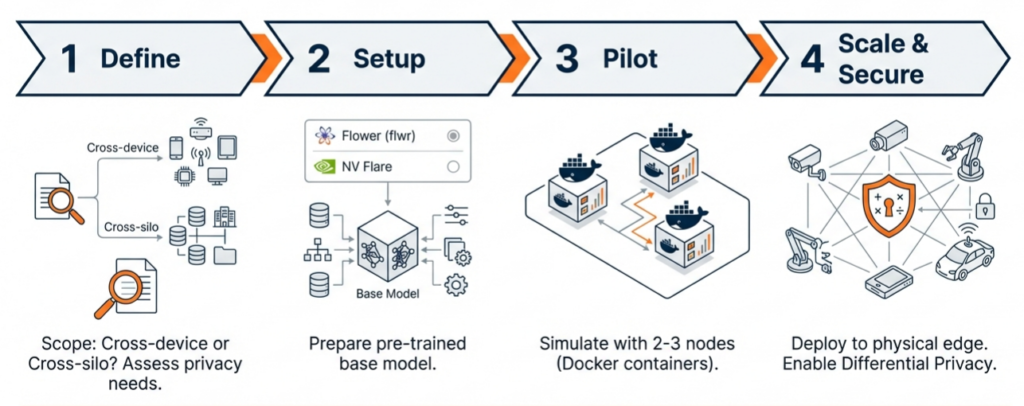
As frameworks like Flower and platforms like Senatr mature, and as edge hardware becomes more powerful, Federated Learning is poised to become the standard operating procedure for Industry 4.0 and 5.0. It allows competing entities to collaborate on safety and efficiency, ensures compliance with strict data regulations, and ultimately, builds a smarter, more resilient manufacturing ecosystem. The future of manufacturing is not just connected; it is federated.
Let Klyff help you manufacture better with federated learning.