Safety incidents happen fast. In many cases, by the time an alert travels from your factory floor to the cloud and back, someone could already be hurt. In fact, we’ve seen this happen in real environments. The system flags the issue a few seconds later, but by then, the moment has already passed. As a result, no one notices in time, no one intervenes, and the risk remains.
In this blog, we build a real-time worker safety system that runs inference right on the edge, on the industrial PC sitting on your factory floor, with no cloud round-trips. No waiting. The moment someone’s missing PPE, an alarm fires locally and a message hits your dashboard in under 100 milliseconds.
We’ll use Intel’s DL Streamer to handle the video pipeline, OpenVINO to optimize every ounce of performance from your models, and Klyff Inspeqtr to transform raw detections into actionable insights. You’ll receive a comprehensive walkthrough of the architecture, from camera to detection to alert.
Why Edge AI for Worker Safety?
The Challenge: Data Gravity and Latency
The industrial sites operate dozens of video streams simultaneously. Transmitting all this footage to the cloud introduces three critical problems:
- Unacceptable Latency: Round-trip latency of 100-500ms defeats real-time decision making. By the time an alert reaches the site, a dangerous moment has already passed.
- Data Privacy & Sovereignty: Continuous surveillance footage raises regulatory and privacy concerns.
- Operational Cost: Cloud inference pricing compounds with scale; a 10-camera site running 24×7 will be costly.
The Edge AI solution
The Intel Open Edge platform runs inference directly on industrial PCs at the edge, eliminating unnecessary video transfer. It sends only metadata and alerts upstream, not raw video. This approach delivers:
- Latency < 100ms: Inference happens locally; decisions trigger immediately.
- Bandwidth Savings: Only event metadata (detections, timestamps, violations) flows to the cloud.
- Data Privacy: The system keeps video inside the facility and logs only structured insights.
What the Intel Open Edge Platform Enables
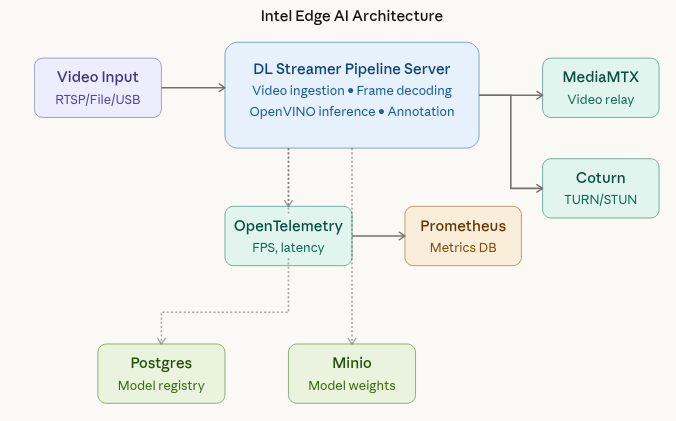
The Worker Safety Gear Detection sample uses a microservice-based architecture running on an industrial PC. At the center is the DL Streamer Pipeline Server, which ingests video and runs the inference pipeline. MediaMTX handles video streaming, while Coturn ensures reliable WebRTC connectivity across network boundaries using TURN/STUN protocols. Open Telemetry Collector and Prometheus provide metrics so operators can confirm performance and availability. Postgres and Minio back the model registry, providing persistence for models and metadata.
These services give the platform a balance of control and flexibility. You can tune performance at the pipeline level, change video sources without redesigning the system.
From Camera to Decision
The system supports three input sources: file, RTSP, and webcam. A file source lets you replay a known scenario. In production, the same pipeline can take RTSP from a fixed camera or a USB webcam attached to the edge device. The pipeline remains the same across sources, so you can change the input without changing the inference logic.
Once the pipeline starts, the DL Streamer Pipeline Server processes each frame, runs the model, and overlays the detection results. It streams the output via WebRTC to a browser, making it easy to display safety status without requiring a dedicated client application. This goes beyond a simple video feed; it operates as a continuously monitored service with measurable performance.
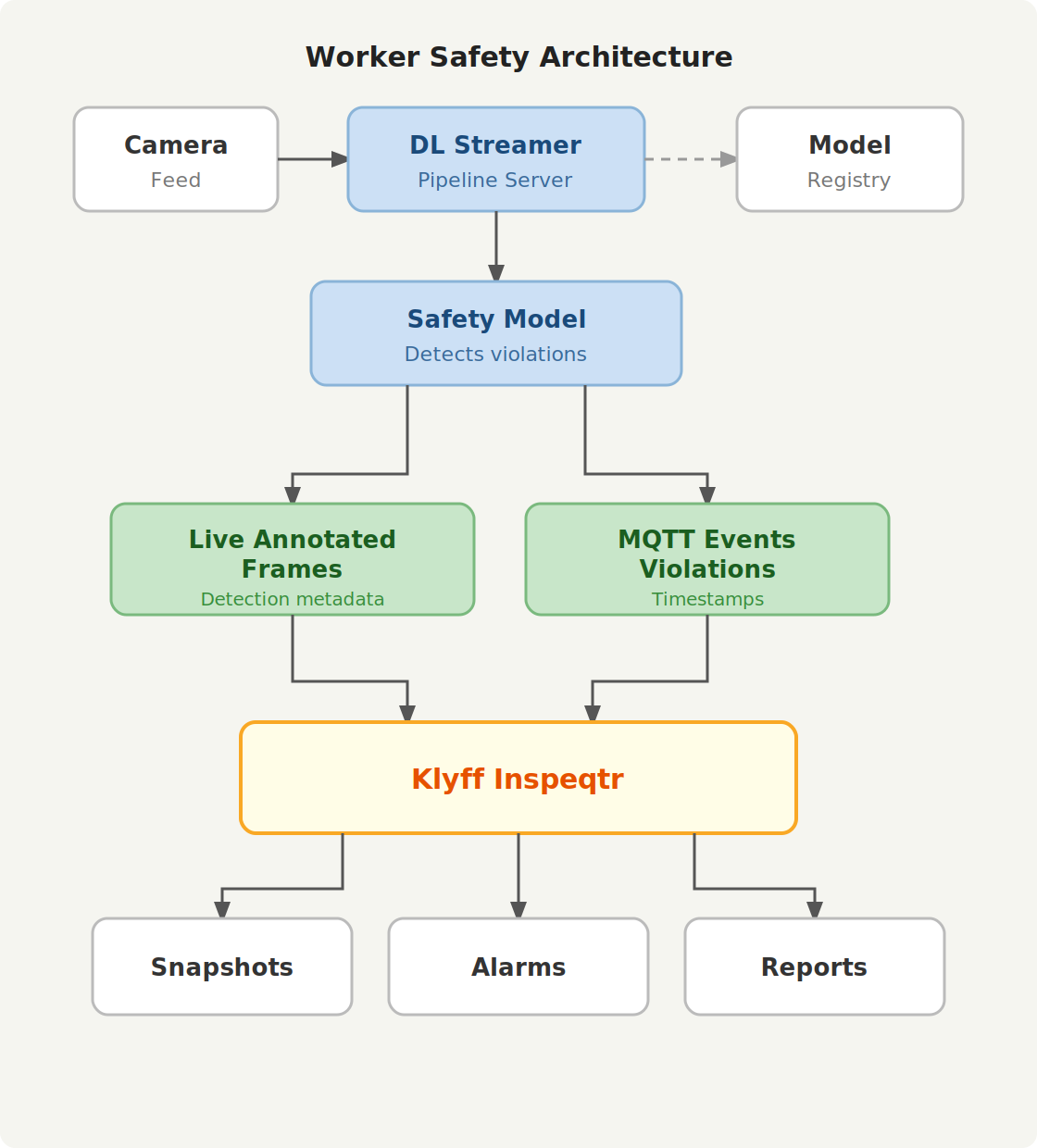
Technical Working (From Request to Result)
We can describe the worker safety system as a structured, observable pipeline:
- A REST request starts the pipeline instance. The request can define the `source`, `destination
`, `metadata`and `parameters` sections. - The DL Streamer Pipeline Server opens the source and performs frame decoding, then runs inference with the configured model and device target.
- The system draws detection results as overlays and pushes them to the WebRTC output so a browser can view the annotated stream.
- The system emits telemetry for FPS, latency, and health, and the Open Telemetry Collector exposes the metrics to Prometheus.
- The pipeline instance ID returned by the start request is used for status checks, model updates, and shutdown.
[
{
"pipeline": "worker_safety_gear_detection",
"payload": {
"source": {
"uri": "file:///home/pipeline-server/resources/videos/Worker.avi",
"type": "uri"
},
"destination": {
"frame": {
"type": "webrtc",
"peer-id": "worker_safety"
},
"metadata": {
"type": "mqtt",
"topic": "worker_safety_gear_detection",
"publish_frame": true
}
},
"parameters": {
"detection-properties": {
"model": "/home/pipeline-server/resources/models/worker-safety-gear-detection/yolo11n.xml",
"model-proc": "/home/pipeline-server/resources/models/worker-safety-gear-detection/model_proc.json",
"device": "CPU"
}
}
}
}
This is the key technical takeaway: video ingestion, inference, visualization, and telemetry are all part of one managed edge pipeline, and each step is independently observable.
OpenVINO Model Optimization & Deployment
OpenVINO provides a highly optimized inference runtime for Intel hardware in edge AI deployments.It takes your trained model from any framework (PyTorch, TensorFlow, ONNX) and compiles it into an optimized Intermediate Representation (IR) — two files: .xml (graph) and .bin (weights) — that run blazing fast on Intel hardware.
Export and Convert a YOLO Model
# Step 1: Export YOLOv8 to ONNX
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
model.export(format='openvino', imgsz=640)
# Ultralytics handles OVC conversion automatically!
INT8 Quantization
OpenVINO’s Post-Training Quantization (PTQ) converts 32-bit floating-point weights to 8-bit integers, delivering:
- Compressed Model: Reduced memory footprint means faster model loading and lower storage overhead.
- Faster Inference: CPU-based inference on modern Intel hardware
- Minimal Accuracy Loss: Calibration on a representative dataset (100–500 images) typically results in <1% accuracy drop.
For details on implementing quantization and measuring its impact, see the What, why, and how of Quantization on Edge AI
OpenVINO IR models do not include preprocessing or output decoding logic. You must define a model_proc.json file to handle input preprocessing, output parsing, and label mapping.
{
"json_schema_version": "2.2.0",
"input_preproc": [
{
"params": {
"resize": "aspect-ratio",
"range": [
0.0,
1.0
]
}
}
],
"output_postproc": [
{
"converter": "yolo_v8",
"confidence_threshold": 0.5,
"iou_threshold": 0.45,
"labels": [
"Hardhat",
"Mask",
"NO-Hardhat",
"NO-Mask",
]
}
]
}
Field Explanation:
- input_preproc: Defines how input frames are prepared. ‘aspect-ratio’ preserves the input image’s aspect ratio while scaling to the model expected size.
- converter: Specifies the output post-processing logic. It applies non-maximum suppression (NMS) and confidence filtering.
- confidence_threshold: Detections with confidence < 0.5 are discarded, reducing false positives.
- iou_threshold: Intersection-over-Union (IoU) threshold for NMS; boxes with IoU > 0.45 are merged.
- labels: Human-readable class names matching the model’s output indices.
IoT Platform Integration: From Inference to Action
Inference results become valuable only when they flow into operational systems. The Worker Safety system integrates with IoT platforms like Inspeqtr through MQTT, transforming raw AI detections into structured, actionable events.
Klyff Inspeqtr Integration
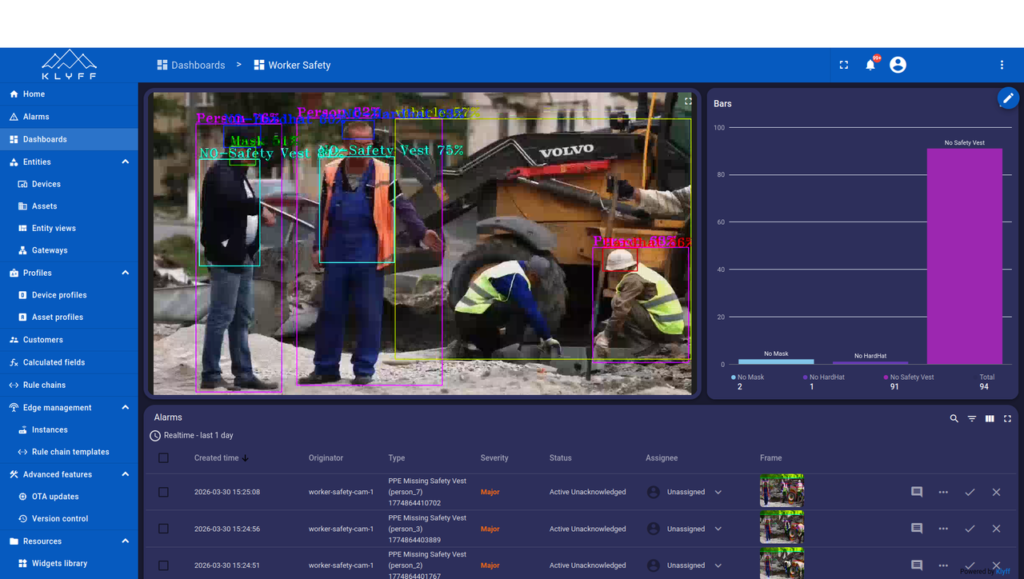
A workplace safety system requires alarms, dashboards, historical data, live monitoring, and fast supervisory response. To enable this, a custom MQTT converter processes incoming detection messages and converts them into the format expected by Inspeqtr.
The converter parses inference metadata, extracts violation labels, and maps them to structured telemetry, device attributes, and alarms associated with the device. Each event is timestamped and enriched with context for downstream processing.
The system generates alarms programmatically by mapping violation types to predefined alarm categories and severity levels. To prevent duplicate alerts, alarms are rate-limited based on (device, person, violation) tuples.
This integration converts raw AI inference into a reliable, real-time monitoring and alerting pipeline suitable for industrial safety operations.
You can find the complete source code on GitHub: https://github.com/KlyffHanger/Inspeqtr-Safety
Conclusion
Worker safety is a high-stakes, high-visibility use case where real-time decisions matter. The Intel Open Edge platform, along with Klyff Inspeqtr, as demonstrated by the Worker Safety Gear Detection sample, shows how to move safety intelligence to the edge without sacrificing observability or model agility. This approach delivers a system that ingests video from real site cameras, detects PPE in real time, streams results to a browser, and adapts as conditions change.
Get in touch with us for us to help you with your Automated Quality Inspection scenarios. We are just a message away.