


Adaptive Predictive Maintenance
On device inference becomes inaccurate with each passing day. Read how Klyff handled on-device training to keep your models accurate.

Solder Joint Inspection
Read how Klyff helped reduce false positive rate to <2% and reduce latency from 120ms to 8ms thus resulting in huge cost advtange

PPE Compliance in Chemical Plant
Klyff helped a global chemical manufacturer to ensure all workers wore Hazmat suits and respirators in "Zone 1" areas through federated learning
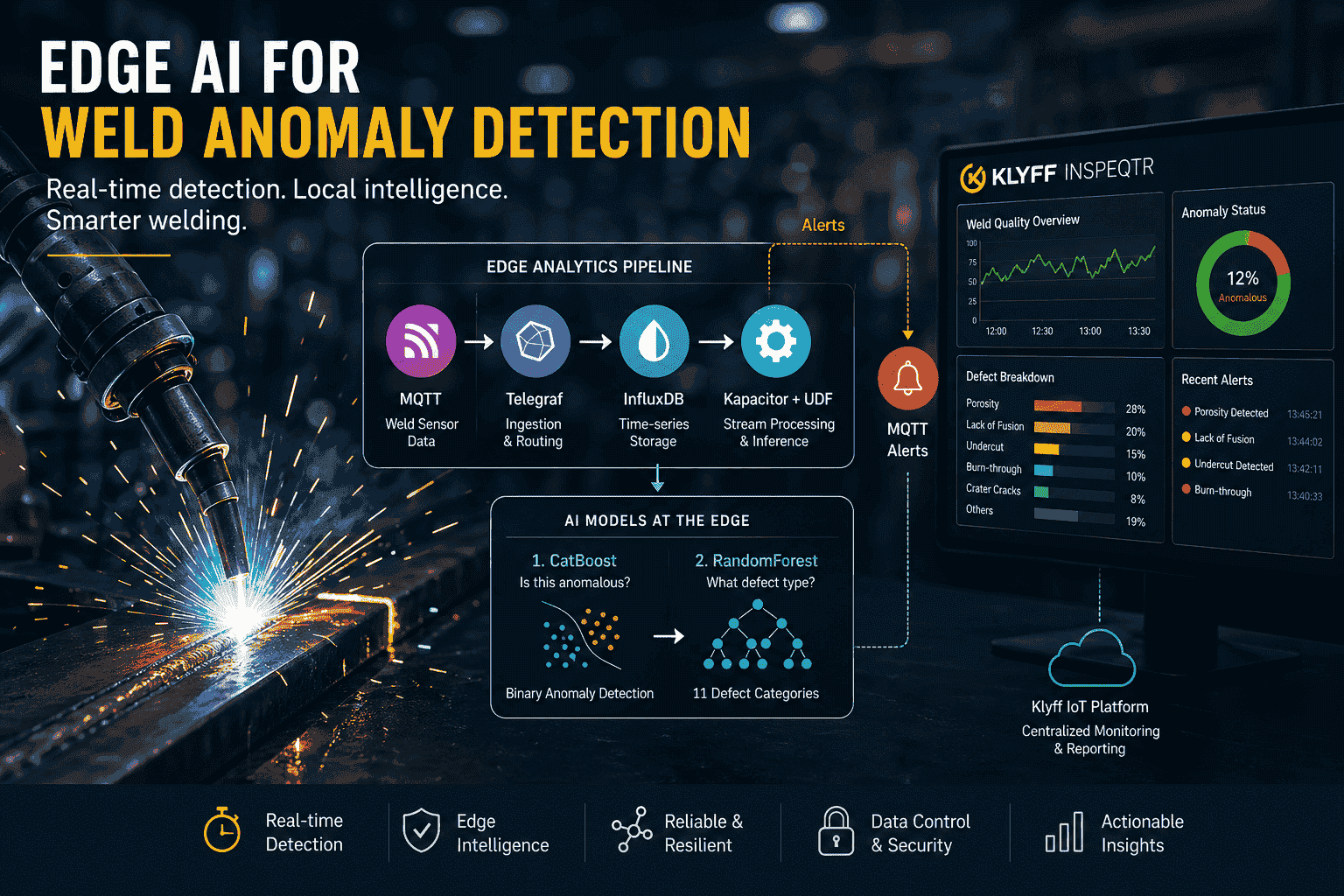
Weld Anomaly Detection using Edge AI
In modern manufacturing, weld quality directly affects product reliability, safety, and production efficiency. A defective weld can lead to rework...
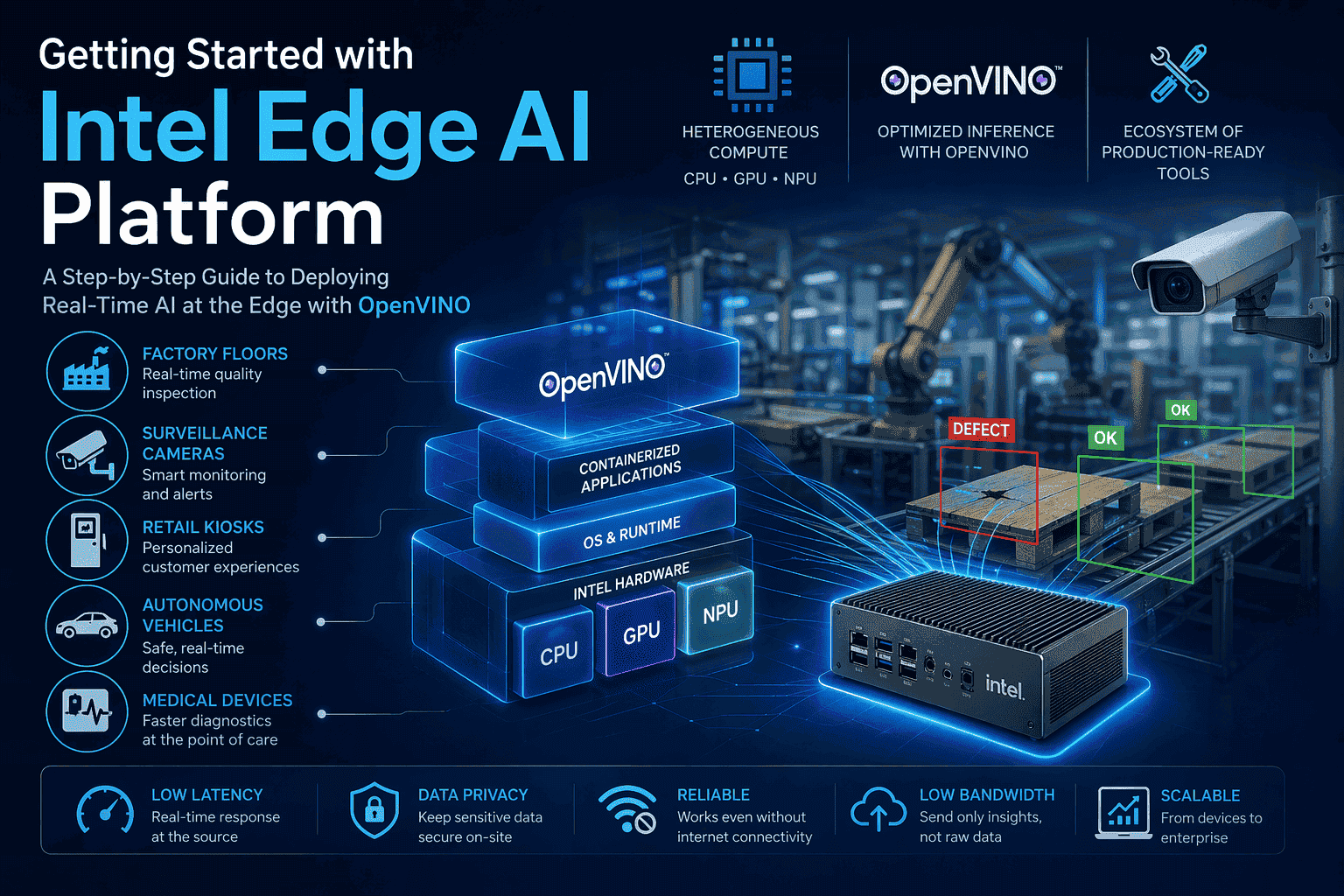
Get started with the Intel Edge AI platform
Intel Edge AI platform is a comprehensive suite of tools, hardware, and frameworks designed to deploy artificial intelligence workloads directly...

Real-Time Weld Porosity Detection Using Edge AI
Most welding lines still rely on manual inspection or post-process testing. Inspectors visually check weld beads, look for defects, and...