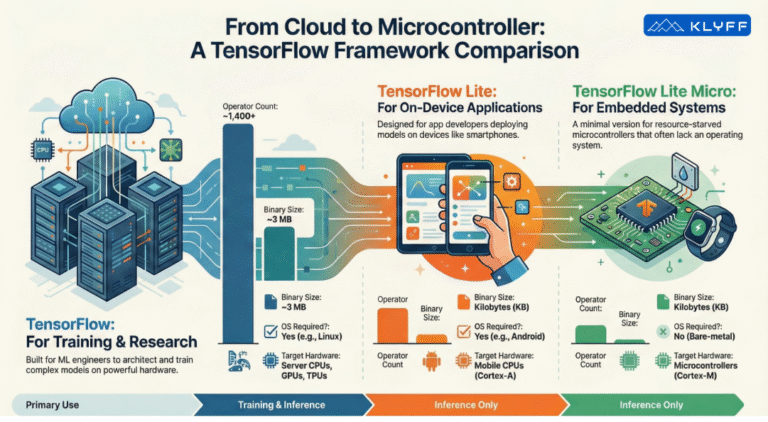
Over the last few weeks, we have gone through the details of the effort required to get up and running with an Edge AI solution. In this post, we will summarise it all together and offer a tool to effectively validate your readiness.
This assessment is divided into 5 major sections to evaluate your readiness in the areas of
- Problem Framing
- Dataset readiness
- Design considerations
- Development
- Deployment
Let us go through a summary of what it takes to develop a successful Edge AI solution.
The Workflow
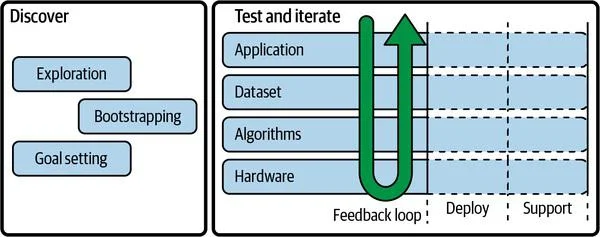
The workflow can be divided into two major parts
- Discover – Understand the problem, resources at your disposal, and space for possible solutions.
- Test & Iterate – This continuous process runs from the initial prototype to production. There is a lot of feedback between different phases, and the product keeps on improving as time goes on.
Problem Framing
The biggest question to answer here is whether the problem at hand does need an Edge AI solution or can it be solved without it. There should be a very good reason for solving it at the edge. You will be inundated with problems like low compute, tough embedded coding, firmware upgrades, and security at the edge.
Next question to answer is whether ML is needed on the edge or not. Practically if the solution be built without ML and just with a rule engine then one should go with that. There are drawbacks to using ML on the edge.
Next, one should consider the feasibility of the solution from the lenses of business, dataset, technology and ethics.
Dataset Readiness
Datasets are absolutely crucial for machine learning projects where data is used to train models; however, they are also important in an Edge AI application, even if it does not need machine learning. It is needed to select effective signal processing techniques, design heuristic algorithms, and test the application under realistic conditions. This is the most difficult, time-consuming, and expensive part of any Edge AI project.
You should be able to determine an ideal dataset along with the quality and quantity of data needed for your solution. It is important to understand the process of estimating how much data is needed.
Next comes the data storage along with considerations like the amount of metadata that needs to be stored, whether the data needs to be sampled, if yes, what would be the sampling considerations, and sample sizes. The data should be free from noise and errors for your use case. A watch should be kept on the drift in data as the time elapses.
Once the raw data is collected, next comes the journey of data preparation, which involves steps like Labelling, Formatting, Cleaning, Feature Engineering, Splitting and Augmenting of data.
Designing the solution
Consideration of design goals broadly under the categories of Systemic, Technical, and Value. The definition of these goals needs input from project stakeholders and domain experts. These goals should be developed taking the good design principles into account.
Next is the architectural design, working through the layers of device, edge, and the cloud. One should consider the algorithms to be used, the sequence in which they would be called, and any postprocessing steps needed to create business value.
Develpoment
Once the basic design is ready, one can get into development. Remember that design and development are iterative steps. One will feed into the other, and they need to go along until the solution meets all the design goals.
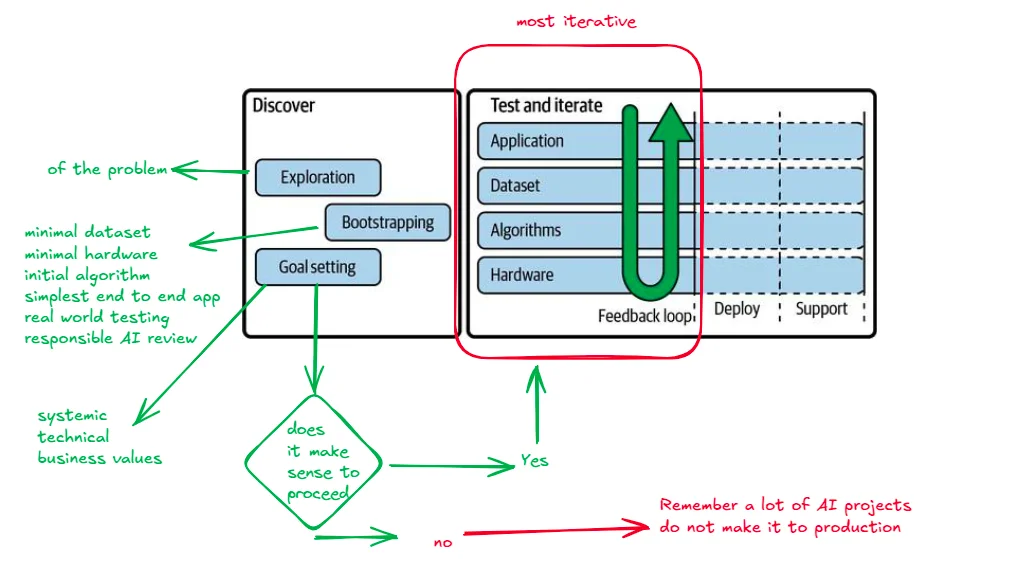
Four major focus areas of application, dataset, algorithm, and hardware go hand in hand. During the initial phase, the algorithm might be waiting for the dataset, and the hardware might be waiting for the algorithm. The process is always iterative, and at the end of every iteration, you will need to make a call on whether it makes sense to go further.
Deployment & Maintenance
You would have to define the metrics to ascertain that the deployed product is meeting its goals. Whether the algorithms fall in the ranges defined, is the computational performance up to the mark?
The series of tasks that need to be addressed pre-deployment, mid-deployment, and post-deployment. Support involves measuring the drift. Drift is a natural phenomenon and should be dealt with. When drift happens, our dataset is no longer the real representation, and a new dataset needs to be collected for the current conditions. To identify the drift, the calculation of summary statistics is handy. These are measurements like mean, median, standard deviation, kurtosis, or skew of readings for a particular sensor. Summary statistics give an indication of whether the drift is happening or not.
Finally is the decision on the terminating criteria, which allows for evaluating when the system should retire.
Conclusion
As you notice, it takes quite a lot to get a successful Edge AI solution to fruition. Our assessment tool will give you a good idea of where you stand as a team to deliver this successfully.
The results of the assessment will point out the areas that you should focus on further. To get a better understanding of the results or to use us as a sounding board for your success, you can always reach out to us and discuss. The Klyff team would love to help you achieve your goals on the edge.