In the previous post, we discussed the various design considerations for an Edge AI solution. Now, let us look at how to develop one and what is the right way to develop an Edge AI solution.
Always Iterative
The Edge AI workflow is an inherently iterative process. Once the discovery is made, the most radical iteration happens in the Test and Iterate cycle. Once this part is complete, we can go to deployment and support which are less iterative than the middle section.
Start with discovery
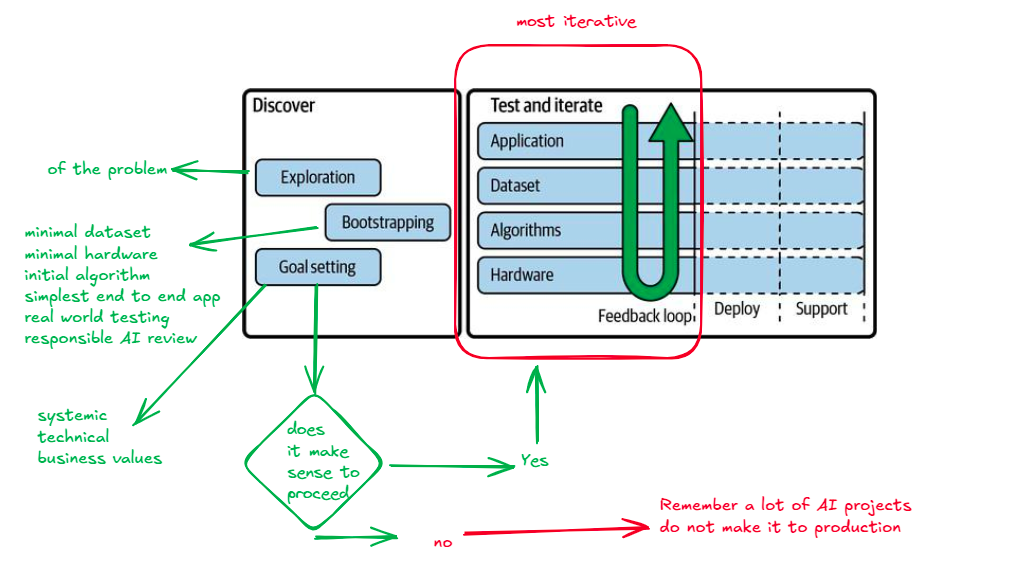
Test and Iterate
Four major focus areas of application, dataset, algorithm, and hardware go hand in hand. During the initial phase, the algorithm might be waiting for the dataset and the hardware might be waiting for the algorithm. In such scenarios, work with the general-purpose hardware until you feel ready for custom.
There needs to be a strong feedback loop between the four focus areas
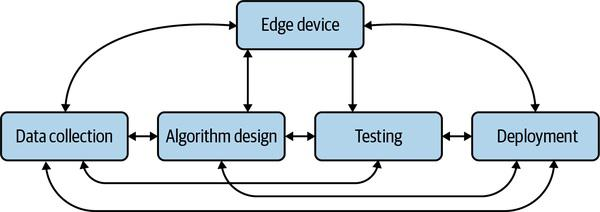
There might be iterations within each of these as well. For example, the dataset might evolve after splitting it into training, validation, and testing. Once the data and the algorithm are finalised we might feel constrained with the hardware which might trigger a change to the algorithm and so on. The iterative work needs MLOps to take care of artifacts, datasets, models, training scripts, and all the dependencies they bring with them.
Model card
Once the algorithm is taking shape, it is important to document it for future users and uses with a model card. This has information on how it has been trained, results against benchmarks, the problem that it solves, and intended uses.
Deployment
Usually done in 2 phases
- Deploying software on the hardware device
- Deploying hardware devices to the real world
Deploying early and often is desirable to get real feedback. Devices should be added slowly on a sample set first to validate and adjust your assumptions.
Support
Edge AI project is never really finished. It enters a gradual phase of monitoring and maintenance. This is due to the drift and shift in data that affects the model performance and causes it to degrade after some time. There needs to be a constant evaluation of the product to analyze if it still meets the goals that it was built for. Sometimes more drastic changes like changing the algorithm might be necessary than just training it with updated datasets.