In previous posts, we have discussed the sensors, processors, and algorithms that allow us to build solutions at the edge. Now, we will start providing a roadmap for working with Edge AI. We will focus on considerations to build the Edge AI solution.
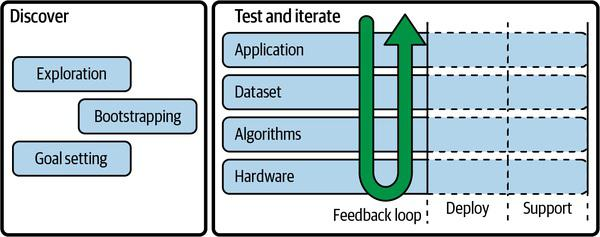
Workflow of an Edge AI Project
The workflow can be divided into two major parts
- Discover – Understand the problem, resources at your disposal, and space for possible solutions.
- Test & Iterate – This continuous process runs from the initial prototype to production. There is a lot of feedback between different phases and the product keeps on improving as time goes on.
As a part of the two parts above, understanding the social factors and risks throughout development allows us to build an ethical AI design.
A typical Edge AI workflow looks like this with a lot of feedback and iteration between application design based on application needs, dataset collection, choice of algorithm, and the type of hardware availability.
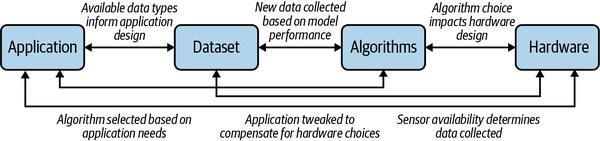
Application – Does the problem need an Edge solution?
For a problem to be fit for Edge AI, we have to consider the BLERP analysis along with the understanding of whether this problem can be solved without the edge. There should be a very good reason for doing it at the edge. Solving at the edge requires us to consider these constraints
- Writing embedded code is tough when working with small targets. The simpler the code the better. If the code is complex, do it on the cloud
- Limited compute to work with. Forget running LLMs on an edge device
- Updating edge firmware is at the risk of bricking the edge by a bug or power outage during an update
- As the edges grow the solution can become expensive than the cloud
- Controlling security on an edge is more complicated than the cloud
If the BLERP analysis does not make a very compelling case for building on the edge, the cloud server should be preferred for any kind of application. A multi device architecture where signal processing happens on the device and the major processing happens on the cloud is also worth considering (e.g. smart speakers)
Does the Edge solution need machine learning?
There is typically a choice between ML and rule-based or heuristic solutions. Heuristics are based on strict rules that could be easy or complex but are mathematically proven and guarantee a fairly high level of accuracy. For example, insulin dosage based on the blood glucose level, driver assist feature using computer vision, guidance system for satellites, and water kettle shutoff when a particular temperature has been reached.
Often DSP systems are used along with rule-based systems. For example, driver assist would use image feature detection to reduce a complex image into set of simple vectors representing line markers for the rule-based system to determine whether to steer left or right.
If there’s a rule-based solution to your problem, you should almost certainly choose it. Many problems can be solved in an elegant manner using rules and heuristics, and they can prove much easier to develop, support, and interpret than the machine learning alternative. They also tend to be far less demanding in terms of computational power.
Scenarios where the rules cannot be applied easily like when dealing with noisy, high-frequency sensor data or there are a lot of variables to make rule processing difficult and inefficient. Too much research would be needed to come up with even a model of rules then ML could be considered. One of the strengths of machine learning, especially deep learning models, is that given enough data they can learn to account for noise. During training, the parameters of the model are tuned in such a way that they filter out the noise from the data, leaving just the important information—which can be used to make a decision.
Drawback of an ML solution
- Data is the major piece, it is hard to get all types of data which has been labeled. It would only be able to give results for situations that it has seen in the data before
- As the model becomes more complex, it is hard to reason with the results or the explainability of the model. Further, unlike the rule-based models with a definite answer, ML models would give a fuzzy probability distribution with a potential answer. This is not encouraging in situations like medical, automotive, or aerospace
- ML bias based on the data
If your solution can be built without ML then that is how it should be built. The best ML is no ML
Checklist to decide if ML might be appropriate
- There is no existing rule-based solution, and you don’t have the resources to discover one.
- You have access to a high-quality dataset or collecting one is within your budget.
- Your system can be designed to make use of fuzzy, probabilistic predictions.
- You do not need to explain the exact logic behind your system’s decisions.
- Your system will not be exposed to inputs beyond those reflected in its training data.
- Your application can tolerate a degree of uncertainty.
How to determine the feasibility of the project
- Moral feasibility – Can the solution cause harm to someone? Can the required data be obtained without violating any rights, individuals, or groups? Is testing possible without any violations of rights? Have the risks been identified and documented – what if it produces incorrect results? Does the application work for all users? What about users with different accents? Ethics is all about people and processes
- Business feasibility – Does it produce a return on investment? Can more work be done with the same budget? Role-play and test different scenarios with Wizard of Oz prototyping. Other constraints of expertise, timeline, budget, and support needed to run the project in production
- Dataset feasibility – How much data is needed to train the model either ML or heuristic? Is it possible to obtain this data easily?
- Technology feasibility – Map the problem against the AI concepts
- Device choices / Sensors – how is data collected, and which devices need to be used? See the device capability chart here
- Data formats – what kind of signals
- Feature engineering – options available for processing raw signals
- Processors – how much compute based on cost and energy is available
- Connectivity – type of communication
- Problem type – classification, regression, object detection & segmentation, anomaly detection, clustering, dimensionality reduction, transformation, or other
- Rule-based or ML
- ML algorithm
- Application architecture – single edge device, hybrid architecture, collection of devices. The architecture choices could be further divided into
- No technical solution and it is just handled manually
- Cloud-based AI – each edge device streams data to the cloud
- Edge Server – edge devices speak on an on-prem edge server via the network
- On-device compute – MCUs run the model on the device
- On-device compute with sensor fusion – MCUs working with sensors for video, audio, radar, etc
Once you do the feasibility analysis, you might discover new constraints that will warrant running another iteration for analysis.