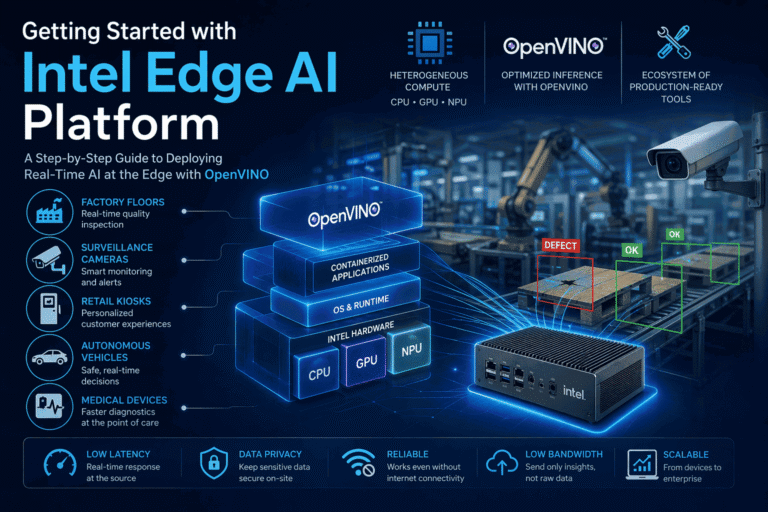
If you are in the AI world today, you will hear about different types of processing units depending on whom you are talking to. Sometimes, it is hard to remember how many of them exist and where you can use them. In this post, we will try to list down the most widely used processing units along with their applications and other considerations.
Different processing units are designed with specific architectural optimizations for distinct computing tasks. The key difference lies in their balance of versatility vs. specialization and sequential vs. parallel processing capabilities.
Here is a breakdown of
Common Processing Units:
| Unit | Full Name | Primary Use Case | Processing Style |
|---|---|---|---|
| CPU | Central Processing Unit | General-purpose computing, running OS & applications | Sequential (few powerful cores) |
| GPU | Graphics Processing Unit | Graphics rendering, machine learning, scientific simulation | Massively Parallel (thousands of smaller cores) |
| NPU | Neural Processing Unit | Energy-efficient AI tasks on mobile/edge devices | Specialized Parallel (optimized for neural nets) |
| LPU | Language Processing Unit | Accelerating large language models (LLMs) and NLP tasks | Highly Specialized Parallel (optimized for linguistic computations) |
| TPU | Tensor Processing Unit | Large-scale AI/deep learning training and inference (Google’s custom chip) | Highly Specialized Parallel (optimized for tensor operations) |
| DPU | Data Processing Unit | Data center tasks like networking, security, and storage management | Offloading/Specialized I/O (data movement optimization) |
| APU | Accelerated Processing Unit | A single chip combining a CPU and an integrated GPU | Balanced (cost/power efficiency for general use) |
Key Differences Explained
- CPU (Central Processing Unit): The “brain” of the computer, the CPU is highly versatile and excels at complex logic and sequential tasks (processing instructions one after another). It has a few powerful cores optimized for single-thread performance and low latency.
- GPU (Graphics Processing Unit): Initially for rendering high-resolution graphics, GPUs are designed with a large number of simpler cores to handle massive parallel computations. This architecture makes them ideal for tasks that can be broken into many smaller, simultaneous operations, such as AI model training, video rendering, and scientific computing.
- NPU (Neural Processing Unit): An AI accelerator designed for maximum energy efficiency, typically for running pre-trained models (inference) on devices with limited power, such as smartphones, IoT devices, and robotics.
- LPU (Language Processing Unit): A newer category of processor specifically tailored for the unique computational demands of large language models (LLMs) and natural language processing (NLP), emphasizing high-speed linguistic computation.
- TPU (Tensor Processing Unit): An Application-Specific Integrated Circuit (ASIC) developed by Google and highly optimized for the tensor (multi-dimensional array) operations that form the core of deep learning. TPUs offer superior efficiency and lower power consumption for specific ML tasks compared to CPUs and GPUs, particularly within the Google Cloud ecosystem.
- DPU (Data Processing Unit): Primarily used in data centers, the DPU offloads data management and networking tasks (like data movement, encryption, and compression) from the CPU, improving overall system efficiency and security.
- APU (Accelerated Processing Unit): A marketing term used by AMD for a single chip that integrates both the CPU and GPU onto the same die, offering a balance of general processing power and basic graphical capabilities in a cost and power-efficient package.
Other specialized processing units
Reconfigurable and Custom Hardware
- FPGA (Field-Programmable Gate Array): FPGAs are integrated circuits designed to be configured or rewired by a customer or designer after manufacturing. Unlike CPUs or GPUs with fixed architectures, FPGAs contain an array of programmable logic blocks that can be configured to perform almost any digital logic function. This makes them ideal for rapid prototyping, applications with evolving specifications, and tasks requiring high-speed, custom data pipelines.
- ASIC (Application-Specific Integrated Circuit): An ASIC is a microchip custom-designed and manufactured for one specific task or application (e.g., Google’s TPU is an ASIC). They offer the highest possible performance and energy efficiency for their intended function, but have extremely high initial development costs and lack flexibility once manufactured.
Specialized Signal and Vision Processors
- DSP (Digital Signal Processor): Optimized for real-time processing of continuous signals like audio, video, and radio frequencies. DSPs are found in modems, smartphones (for noise cancellation and voice recognition), and audio equipment.
- VPU (Vision Processing Unit): A type of AI accelerator specifically designed to accelerate machine vision tasks, such as image recognition, object detection, and autonomous navigation. They typically feature direct interfaces to cameras and emphasize efficient on-chip dataflow.
- ISP (Image Signal Processor): A specialized DSP for processing images, often found within camera systems or mobile device SoCs, to enhance image quality (e.g., noise reduction, color correction) before storage or display.
Future and Experimental Processors
- QPU (Quantum Processing Unit): The central component of a quantum computer. Unlike classical processors that use bits (0s and 1s), QPUs use quantum bits (qubits) to perform certain types of calculations exponentially faster by leveraging quantum mechanics principles like superposition and entanglement.
- Neuromorphic Chip: These experimental chips are designed to mimic the structure and function of the human brain, using artificial neurons and synapses. They are used for energy-efficient cognitive computing tasks like advanced pattern recognition and real-time learning.
- IPU (Intelligence Processing Unit): A category of processor developed by Graphcore focused on graph-based machine learning computations, intended to manage the flow of data within complex neural networks more efficiently than traditional GPUs.
- PIM (Processing-in-Memory): An architectural approach that integrates computation directly into memory chips to reduce the data movement bottleneck between the processor and memory, increasing overall system performance.