Embedded Systems
Embedded systems are computers that control the electronics of physical devices. Devices such as Bluetooth headphones, and brushes to the engine interface of cars. Embedded systems are small for microcontrollers like a digital watch or bigger such as the system that controls a smart TV. They usually perform one specific dedicated task.
Embedded systems have constraints such as low computing power, limited memory, and extremely slow clock rates. They usually run on battery power and need to be very efficient. Programming on embedded systems involves taking care of these constraints and making the best out of the limited resources.
In 2021, an estimated 12.2 billion devices were connected to the Internet, and this number has since grown rapidly. This vast network of objects is called the Internet of Things (IoT) and includes everything from refrigerators to industrial sensors to coffee machines to medical devices. All of these devices have embedded systems containing microprocessors. Since they are at the edge of the network hence they are called edge devices. They can communicate with each other as well as remote servers.
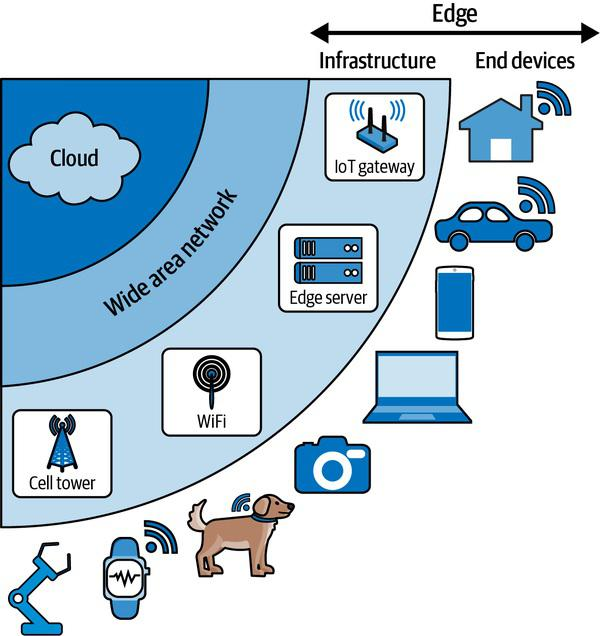
The edge devices are the link between our physical world and the internet. They use various sensors to collect data and pass it on for processing or decision-making. Heart rate, temperature, and acceleration are all examples of data that can be collected with the help of sensors. The Edge Device can then act on this data locally or send it forward for further processing.
These edge devices need to be intelligent. That means that they should know to do the right thing at the right time. Examples are
- Taking a picture when there is a person in the frame
- Opening the faucet when the water bottle is placed under it (as you see at the airports)
- Responding to a question (prompt) with relevant information
- Stopping a machine if it senses an object that could be damaged or get hurt
- Applying brakes if the car is about to crash
It is easy for humans who possess general intelligence to do these tasks but for narrow intelligence edge devices, this is as simple as producing an action based on a precondition.
The edge devices do not need general intelligence. They need narrow intelligence to make decisions based on logic. For example, to stop a car crash it needs to have the current speed and the distance from the other object as the main variables.
current_speed = 25 # In meters per second
distance_from_object = 500 # In meters
seconds_to_stop = 3 # The minimum time in seconds required to stop the car
safety_buffer = 1 # The safety margin in seconds before hitting the brakes
# Calculate how long we’ve got before we hit the other object
seconds_until_crash = distance_from_wall / current_speed
# Make sure we apply the brakes if we’re likely to crash soon
if seconds_until_crash < seconds_to_stop + safety_buffer:
applyBrakes()ML and Edge
Machine learning is a way to discover patterns by running data through algorithms. Trained with the training data set, that is the data and the information as to what that data corresponds to is called a model. For example, feeding a smart camera data on persons and animals and mapping the right data to person and animal allows the model to be built i.e. data and what the data signifies. Now, the machine learning model encounters new data, and based on the training data it can do inference. The ability to understand new inputs is called generalization.
The edge devices produce a firehose of data. This data individually is not very interesting. E.g., an accelerometer would take more than 100 readings a second. These readings by themselves are not interesting but when aggregated over time, they become valuable. Typically and historically, the edge devices are expected to send tons of data to the central location for processing. This is wasteful and also drains the battery of the edge device. Connectivity is expensive and data transmission is battery drain. Hence, making decision on the edge itself on what data to send and what to discard is very important. The edge device could do the processing directly on the device where the data is being captured and pass back aggregated data or even better, useful information back to the central location.
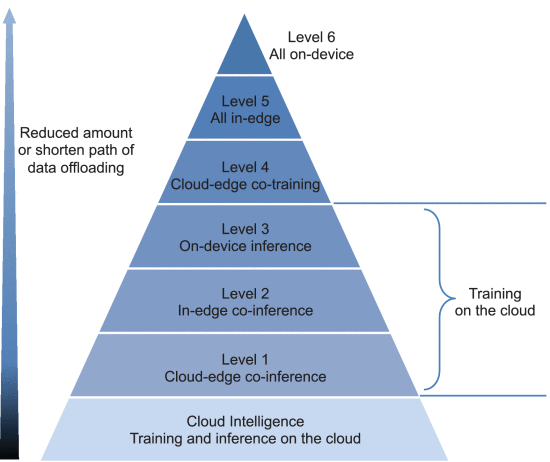
In their paper on edge intelligence, Zhou et al define 6 levels of Edge Intelligence. Level 1 is where training is done on the cloud and the inference is done on both the cloud and the edge. Level 6 is where training and inference are done on the edge devices only.
Embedded ML is the science of running machine learning models on embedded devices. Tiny ML allows this to be done on the most constrained machines like microcontrollers, digital signal processors, and small FPGAs (Field Programmable Gate Arrays). Embedded devices have constraints of computational power and low memory. This raises challenges for many ML models that need ROM to store the model and RAM to handle immediate results generated by inference. Embedded ML is deployed alongside Digital Signal Processing (DSP).
Any sensor gives a lot of data. E.g., an accelerometer gives data for 3 axes x,y, and z. Similarly, a digital microphone gives data about sound level at a particular time. DSP is the practice of using algorithms to manipulate these streams of data before they can be fed into an ML model. The reason to clean data would be to remove noise, outliers, and spikes, extract the most important information from a signal, data transformation from the time domain to the frequency domain, etc. Embedded chips have hardware implementation of the common and needed algorithms of DSP.
Hence from generic to specific, the above concepts could be listed as

BLERP – The benefits of Edge AI
BLERP helps us showcase the benefits of Edge AI and also helps assess if a particular application is well suited for AI.
- Bandwidth – IoT devices collect a lot of data and do not have the bandwidth to transfer it all. This is because it might not have a constant connection to the central location or the cost of sending all the time is too high like in the case of memory and battery constraints. Hence it is forced to discard a lot of data including some useful data as well. For example, it might send events that show change in temperatures if the threshold is breached but it might not send the patterns that show that the machine might fail due to patterns of change. Hence, it is important to run the data analysis on the device itself.
- Latency – Transmission takes time. Even with a lot of bandwidth a round trip would take hundreds of millisecs. A moving vehicle cannot wait for this kind of latency. The edge devices need to be intelligent to make decisions locally in this case. In most cases, this is solved by onboard computers. Sometimes the latency might be minutes even at the speed of light. Like the communication with the Mars Rover.
- Economics: Connectivity is expensive. Connected products are costly and need underlying infrastructure to work. Long-range connectivity, like satellite communication, is expensive. Does LoRaWAN help here? Sometimes, the only connectivity is human intervention. For example, cameras set in the wilderness to track wildlife are enhanced with AI to take only relevant footage and discard the non-relevant ones. Edge devices cannot be dependent on server-side AI as well as then they will have to phone home many times which is expensive to maintain as well.
- Reliability – Devices functioning on their own with edge AI are more reliable than the devices that need to connect to the servers. If they need connectivity then they have to depend on infrastructure and protocols as a part of a complex web of dependencies. When you are dependent on the link layer communication technologies to the internet as a whole you can be as reliable as the weakest link.
- Privacy – There is traditionally a trade-off between privacy and convenience. For convenience, we end up sending a lot of data to the central servers so that they can remember us on any device. Edge AI solves this by processing data locally and only alerts or triggers could be passed on for processing.
Edge AI is helping in all the above scenarios in Smart Parks to study animal behavior, Identify forest fires, screen patients in developing countries, and identify diseases of crops in farms and vineyards.
Edge AI though a subset of AI differs from mainstream AI on the following counts
- Training on the Edge is rare – AI applications are powered by ML. ML involves training a model to make predictions based on labeled data. Once a model is trained it does inference. Training the model requires a lot of computation, memory, and a labeled data set. This is hard to come by on the edge where the resources are scarce and the data is raw and unfiltered. Hence the model training and data cleaning is done elsewhere before the model is deployed to the edge.
- The Focus of Edge AI is on sensor data – Edge devices are the closest to where the data is made. Sensor data is big, noisy, difficult to manage, and arrives at high frequency. An edge device has a limited time frame to collect this data, process it, feed it into an algorithm to make a decision, and then act on the results. Most embedded devices are resource-constrained and do not have the RAM to store and process large amounts of data. Hence the focus is to keep signal processing and AI components as a single system balancing the tradeoffs between performance and accuracy.
- ML models need to be small – Edge devices have slower processors and small memory. A midrange microcontroller might have a few kilobytes of ROM available to store a model. Smaller models may have smaller training datasets on which they are trained and hence might not be very accurate. Hence it is a size versus accuracy tradeoff.
- Feedback learning is limited – The regular AI applications learn from the feedback of the ML models. When all the data is sent to the central servers, patterns can emerge and they can be used to train the model better. For edge devices, there might not be any communication round trip.
- Compute is diverse – The embedded world has a heterogeneous array of device types, coupled with a wide variety of manufacturers each with a unique set of build tools, programming environments, and interfacing options.
- Microcontrollers – 8-bit chips to 32-bit processors
- System-on-chip (SoC) devices running embedded Linux
- General-purpose accelerators built with GPUs
- Field programmable gate arrays (FPGAs)
- Fixed architecture accelerators – they run single-model architecture blazingly fast
- The goal is to be good enough – The goal of regular AI systems is to be highly accurate, no matter the cost. Server-side models can be in GBs and can rely on powerful GPUs to compute and be responsive. For edge devices, the goal is to be good enough with performance and accuracy a tradeoff.
Pingback: Edge AI in Real World » klyff.com
Pingback: Processors at the Edge AI » klyff.com